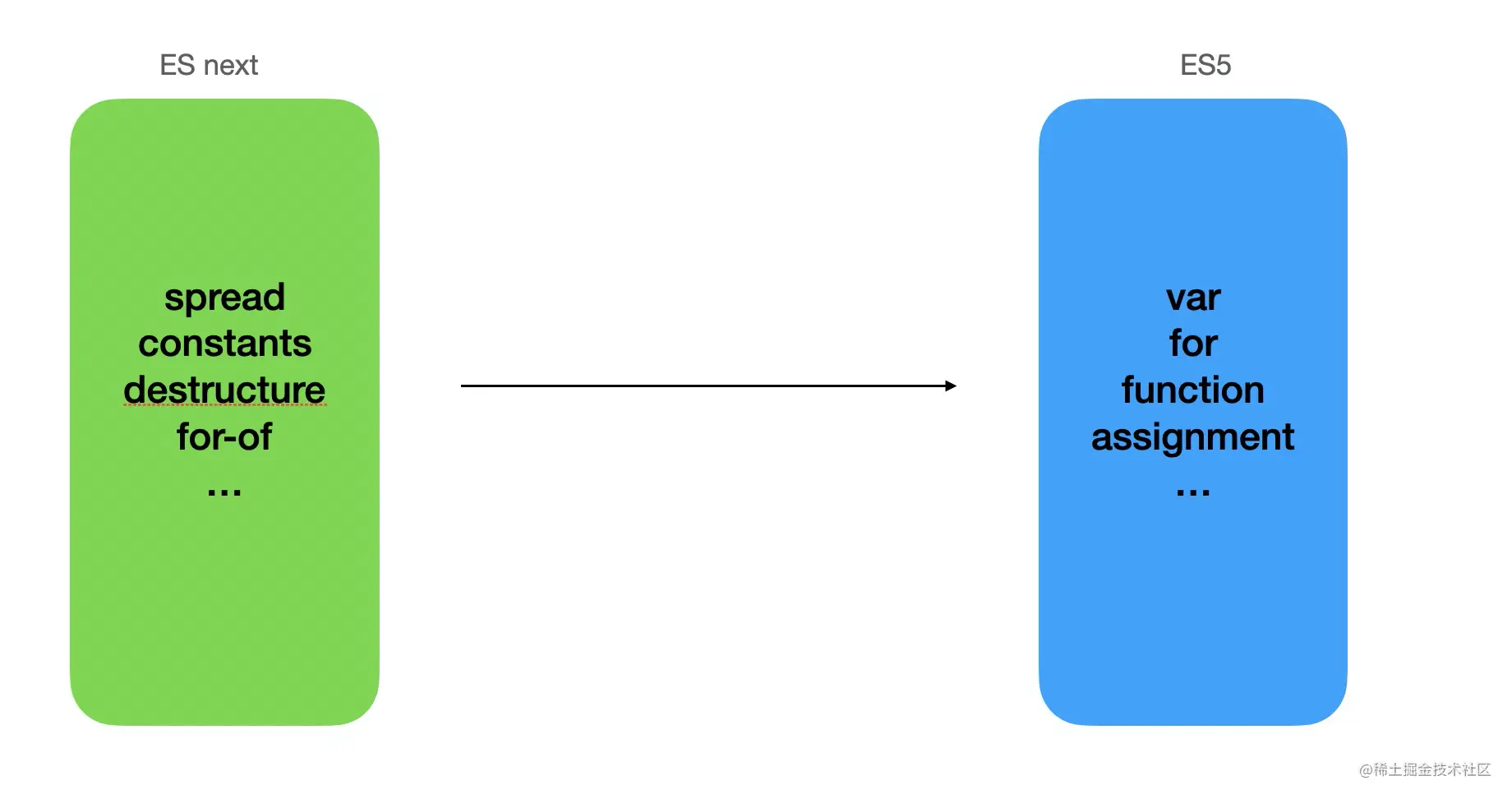
Babel
初识Babel
babel 的用途
转译 esnext、typescript、flow 等到目标环境支持的 js
这个是最常用的功能,用来把代码中的 esnext 的新的语法、typescript 和 flow 的语法转成基于目标环境支持的语法的实现。并且还可以把目标环境不支持的 api 进行 polyfill。
babel7 支持了 preset-env,可以指定 targets 来进行按需转换,转换更加的精准,产物更小。
一些特定用途的代码转换
babel 是一个转译器,暴露了很多 api,用这些 api 可以完成代码到 AST 的解析、转换、以及目标代码的生成。
开发者可以用它来来完成一些特定用途的转换,比如函数插桩(函数中自动插入一些代码,例如埋点代码)、自动国际化等。这些都是后面的实战案例。
现在比较流行的小程序转译工具 taro,就是基于 babel 的 api 来实现的。
代码的静态分析
对代码进行 parse 之后,能够进行转换,是因为通过 AST 的结构能够理解代码。理解了代码之后,除了进行转换然后生成目标代码之外,也同样可以用于分析代码的信息,进行一些检查。
linter 工具就是分析 AST 的结构,对代码规范进行检查。
api 文档自动生成工具,可以提取源码中的注释,然后生成文档。
type checker 会根据从 AST 中提取的或者推导的类型信息,对 AST 进行类型是否一致的检查,从而减少运行时因类型导致的错误。
压缩混淆工具,这个也是分析代码结构,进行删除死代码、变量名混淆、常量折叠等各种编译优化,生成体积更小、性能更优的代码。
js 解释器,除了对 AST 进行各种信息的提取和检查以外,我们还可以直接解释执行 AST。
Babel 的编译流程
编译器和转译器
编译的定义就是从一种编程语言转成另一种编程语言。主要指的是高级语言到低级语言。
高级语言:有很多用于描述逻辑的语言特性,比如分支、循环、函数、面向对象等,接近人的思维,可以让开发者快速的通过它来表达各种逻辑。比如 c++、javascript。
低级语言:与硬件和执行细节有关,会操作寄存器、内存,具体做内存与寄存器之间的复制,需要开发者理解熟悉计算机的工作原理,熟悉具体的执行细节。比如汇编语言、机器语言。
一般编译器 Compiler 是指高级语言到低级语言的转换工具,对于高级语言到高级语言的转换工具,被叫做转换编译器,简称转译器 (Transpiler)。
babel 就是一个 Javascript Transpiler。
babel 的转义流程
babel 是 source to source 的转换,整体编译流程分为三步:
- parse:通过 parser 把源码转成抽象语法树(AST)
- transform:遍历 AST,调用各种 transform 插件对 AST 进行增删改
- generate:把转换后的 AST 打印成目标代码,并生成 sourcemap
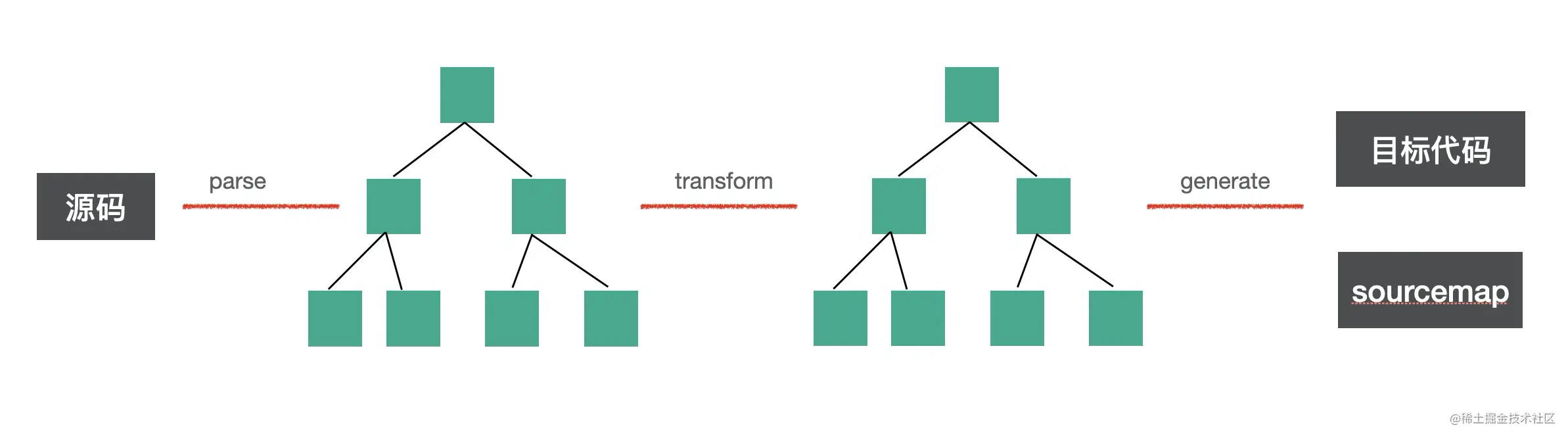
为什么会分为这三步
为了让计算机理解代码需要先对源码字符串进行 parse,生成 AST,把对代码的修改转为对 AST 的增删改,转换完 AST 之后再打印成目标代码字符串。
这三步都做了什么
parse
parse 阶段的目的是把源码字符串转换成机器能够理解的 AST,这个过程分为词法分析、语法分析。
比如 let name = 'guang'; 这样一段源码,我们要先把它分成一个个不能细分的单词(token),也就是 let, name, =, 'guang',这个过程是词法分析,按照单词的构成规则来拆分字符串成单词。
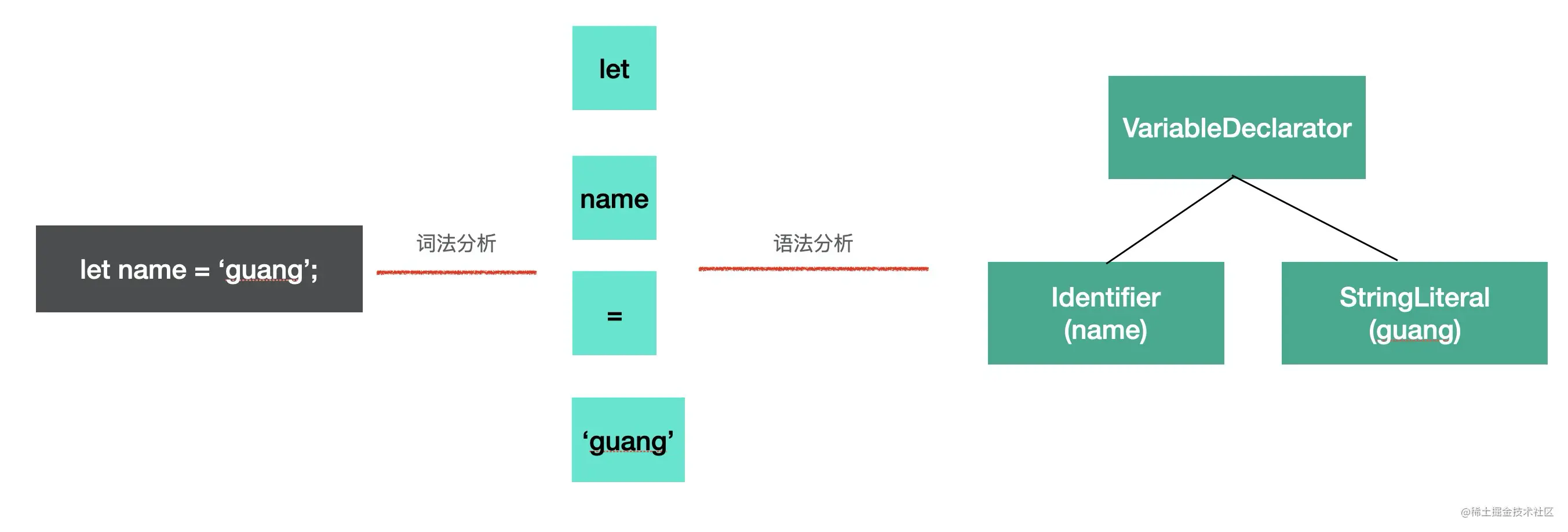
之后要把 token 进行递归的组装,生成 AST,这个过程是语法分析,按照不同的语法结构,来把一组单词组合成对象,比如声明语句、赋值表达式等都有对应的 AST 节点。
transform
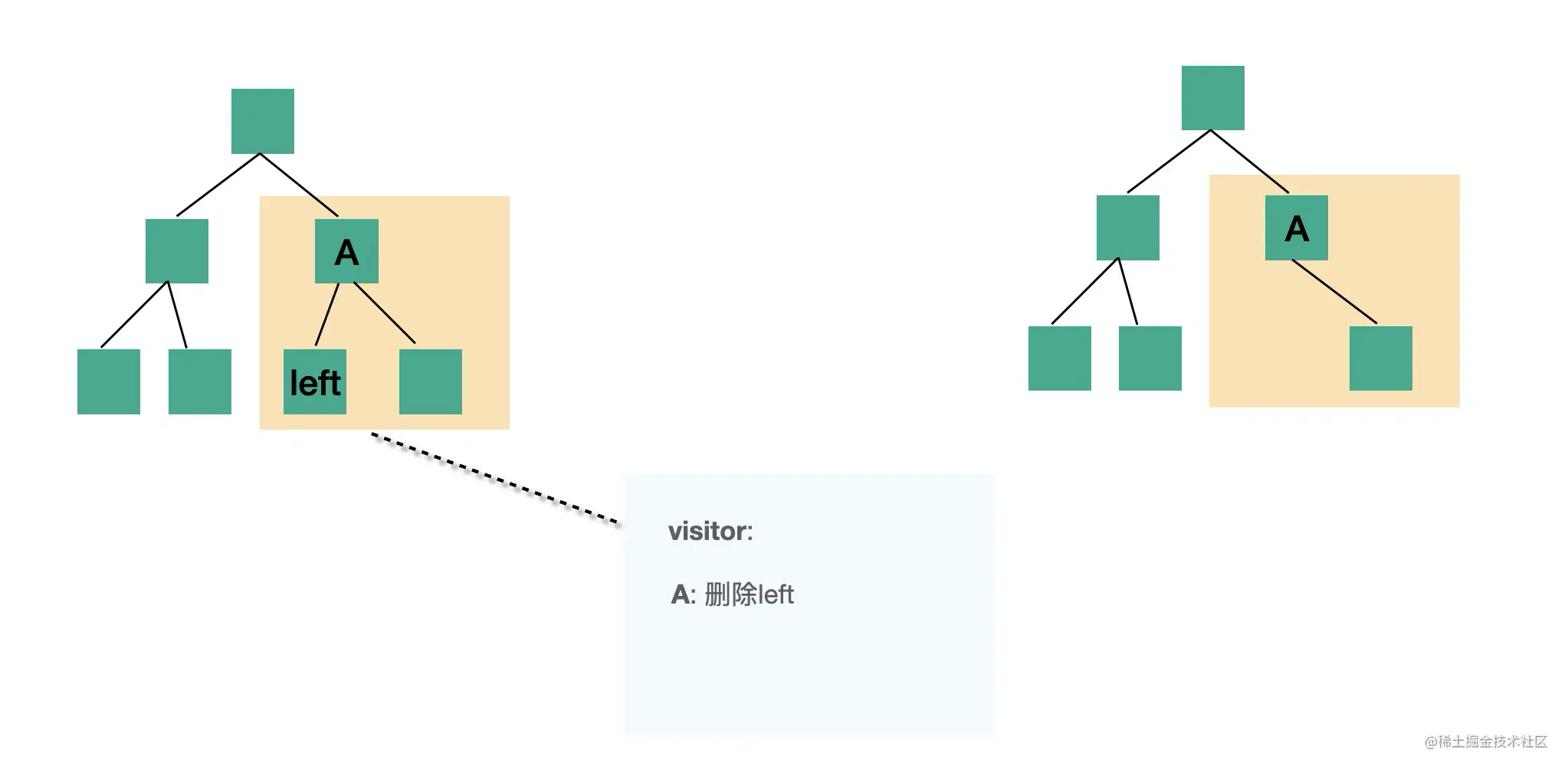
transform 阶段是对 parse 生成的 AST 的处理,会进行 AST 的遍历,遍历的过程中处理到不同的 AST 节点会调用注册的相应的 visitor 函数,visitor 函数里可以对 AST 节点进行增删改,返回新的 AST(可以指定是否继续遍历新生成的 AST)。这样遍历完一遍 AST 之后就完成了对代码的修改。
generate
generate 阶段会把 AST 打印成目标代码字符串,并且会生成 sourcemap。不同的 AST 对应的不同结构的字符串。比如 IfStatement 就可以打印成 if(test) {} 格式的代码。这样从 AST 根节点进行递归的字符串拼接,就可以生成目标代码的字符串。

sourcemap 记录了源码到目标代码的转换关系,通过它我们可以找到目标代码中每一个节点对应的源码位置,用于调试的时候把编译后的代码映射回源码,或者线上报错的时候把报错位置映射到源码
Babel 的 AST
常见的 AST 节点
AST 是对源码的抽象,字面量、标识符、表达式、语句、模块语法、class 语法都有各自的 AST。
Literal 字面量
比如 let name = 'guang'中,'guang'就是一个字符串字面量 StringLiteral,相应的还有数字字面量 NumericLiteral,布尔字面量 BooleanLiteral,字符串字面量 StringLiteral,正则表达式字面量 RegExpLiteral 等。
'gang' // StringLiteral
`gang` // TemplateLiteral
123 // NumericLiteral
/^[a-z]+/ // RegExpLiteral
true // BooleanLiteral
1.23n // BigintLiteral
null // NullLiteral
Identifier 标识符
变量名、属性名、参数名等各种声明和引用的名字,都是Identifer。我们知道,JS 中的标识符只能包含字母或数字或下划线(“_”)或美元符号(“$”),且不能以数字开头。这是 Identifier 的词法特点。
下面这段代码中有多少 Identifier
const name = 'guang';// name
function say(name) { // say、name
console.log(name); // console、log
}
const obj = { // obj
name: 'guang' // name
}
Statement 语句
可以独立执行的单位,比如 break、continue、debugger、return 或者 if 语句、while 语句、for 语句,还有声明语句,表达式语句等。我们写的每一条可以独立执行的代码都是语句。
语句末尾一般会加一个分号分隔,或者用换行分隔。
下面这些我们经常写的代码,每一行都是一个 Statement:
break; // BreakStatement
continue; // ContinueStatement
return; // ReturnStatement
debugger; // DebuggerStatement
throw Error(); // ThrowStatement
{} // BlockStatement
try {} catch(e) {} finally{} // TryStatement
for (let key in obj) {} // ForInStatement
for (let i = 0;i < 10;i ++) {} // ForStatement
while (true) {} // WhileStatement
do {} while (true) // DoWhileStatement
switch (v){case 1: break;default:;} // SwitchStatement
label: console.log(); // LabelStatement
with (a){} // WithStatement
Declaration 声明
是一种特殊的语句,它执行的逻辑是在作用域内声明一个变量、函数、class、import、export 等。
const a = 1; // VariableDeclaration
function b(){} // FunctionDeclaration
class C {} // ClassDeclaration
import d from 'e'; // ImportDeclaration
export default e = 1; // ExportDefaultDeclaration
export {e}; // ExportNameDeclaration
export * from 'e'; // ExportAllDeclaration
Expression 表达式
特点是执行完以后有返回值,这是和语句 (statement) 的区别。
[1,2,3] // ArrayExpression
a = 1 // AssignmentExpression
1 + 2; // BinaryExpression
-1; // UnaryExpression
function(){}; // FunctionExpression
() => {}; // ArrowFunctionExpression
class{}; // ClassExpression
a; // Identifier
this; // ThisExpression
super; // Super
a::b; // BindExpress
Class
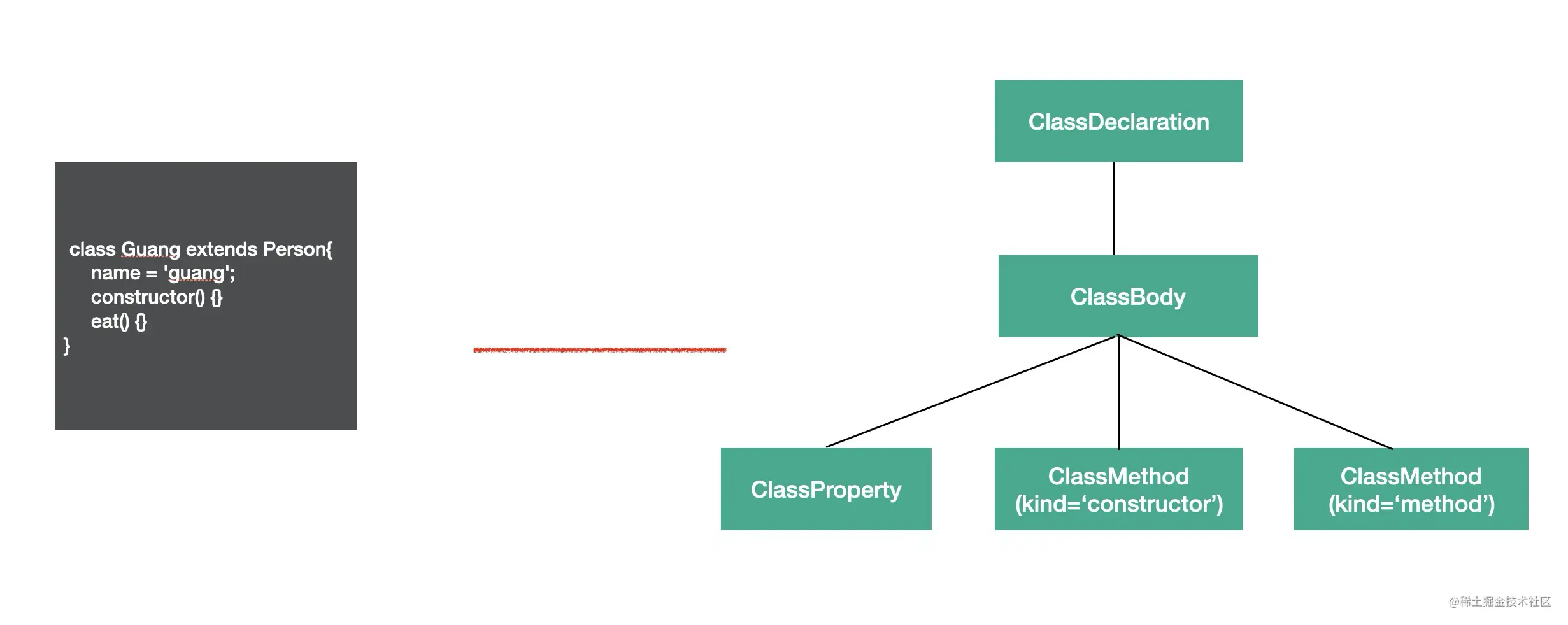
class 的语法也有专门的 AST 节点来表示。
整个 class 的内容是 ClassBody,属性是 ClassProperty,方法是ClassMethod(通过 kind 属性来区分是 constructor 还是 method)。
class Guang extends Person{
name = 'guang';
constructor() {}
eat() {}
}
Modules
es module 是语法级别的模块规范,所以也有专门的 AST 节点。
import
import {c, d} from 'c'; // named import
import a from 'a'; // default import
import * as b from 'b'; // namespaced import
这 3 种语法都对应 ImportDeclaration 节点,但是 specifiers 属性不同,分别对应 ImportSpicifier、ImportDefaultSpecifier、ImportNamespaceSpcifier。
export
export { b, d}; // named export
export default a; // default export
export * from 'c'; // all export
分别对应 ExportNamedDeclaration、ExportDefaultDeclaration、ExportAllDeclaration 的 AST。
Program & Directive
program 是代表整个程序的节点,它有 body 属性代表程序体,存放 statement 数组,就是具体执行的语句的集合。还有 directives 属性,存放 Directive 节点,比如"use strict" 这种指令会使用 Directive 节点表示。
File & Comment
babel 的 AST 最外层节点是 File,它有 program、comments、tokens 等属性,分别存放 Program 程序体、注释、token 等,是最外层节点。
注释分为块注释和行内注释,对应 CommentBlock 和 CommentLine 节点。
AST 可视化查看工具
通过 https://astexplorer.net 查看
AST 的公共属性
每种 AST 都有自己的属性,但是它们也有一些公共的属性:
type: AST 节点的类型start、end、loc:start 和 end 代表该节点在源码中的开始和结束下标。而 loc 属性是一个对象,有 line 和 column 属性分别记录开始和结束的行列号。leadingComments、innerComments、trailingComments: 表示开始的注释、中间的注释、结尾的注释,每个 AST 节点中都可能存在注释,而且可能在开始、中间、结束这三种位置,想拿到某个 AST 的注释就通过这三个属性。extra:记录一些额外的信息,用于处理一些特殊情况。比如 StringLiteral 的 value 只是值的修改,而修改 extra.raw 则可以连同单双引号一起修改。
Babel 的 API
babel 的 api 有哪些
我们知道 babel 的编译流程分为三步:parse、transform、generate,每一步都暴露了一些 api 出来。
- parse 阶段有@babel/parser,功能是把源码转成 AST
- transform 阶段有 @babel/traverse,可以遍历 AST,并调用 visitor 函数修改 AST,修改 AST 自然涉及到 AST 的判断、创建、修改等,这时候就需要 @babel/types 了,当需要批量创建 AST 的时候可以使用 @babel/template 来简化 AST 创建逻辑。
- generate 阶段会把 AST 打印为目标代码字符串,同时生成 sourcemap,需要 @babel/generator 包
- 中途遇到错误想打印代码位置的时候,使用 @babel/code-frame 包
- babel 的整体功能通过 @babel/core 提供,基于上面的包完成 babel 整体的编译流程,并应用 plugin 和 preset。
我们主要学习的就是 @babel/parser,@babel/traverse,@babel/generator,@babel/types,@babel/template 这五个包的 api 的使用。
@babel/parser
babel parser 叫 babylon,是基于 acorn 实现的,扩展了很多语法,可以支持 es next(现在支持到 es2020)、jsx、flow、typescript 等语法的解析。默认只能 parse js 代码,jsx、flow、typescript 这些非标准的语法的解析需要指定语法插件。
它提供了有两个 api:parse 和 parseExpression。两者都是把源码转成 AST,不过 parse 返回的 AST 根节点是 File(整个 AST),parseExpression 返回的 AST 根节点是是 Expression(表达式的 AST),粒度不同。
function parse(input: string, options?: ParserOptions): File
function parseExpression(input: string, options?: ParserOptions): Expression
options 主要分为两类:
- parse 的内容是什么
- 以什么方式去 parse
详细的可以查看文档
parse 的内容是什么
plugins: 指定jsx、typescript、flow 等插件来解析对应的语法allowXxx: 指定一些语法是否允许,比如函数外的 await、没声明的 export等sourceType: 指定是否支持解析模块语法,有 module、script、unambiguous 3个取值:module:解析 es module 语法script:不解析 es module 语法unambiguous:根据内容是否有 import 和 export 来自动设置 module 还是 script
一般我们会指定 sourceType 为 unambiguous。
以什么方式 parse
strictMode是否是严格模式startLine从源码哪一行开始 parseerrorRecovery出错时是否记录错误并继续往下 parsetokensparse 的时候是否保留 token 信息ranges是否在 ast 节点中添加 ranges 属性
@babel/traverse
parse 出的 AST 由 @babel/traverse 来遍历和修改,babel traverse 包提供了 traverse 方法:
function traverse(parent, opts)
常用的就前面两个参数,parent 指定要遍历的 AST 节点,opts 指定 visitor 函数。babel 会在遍历 parent 对应的 AST 时调用相应的 visitor 函数。
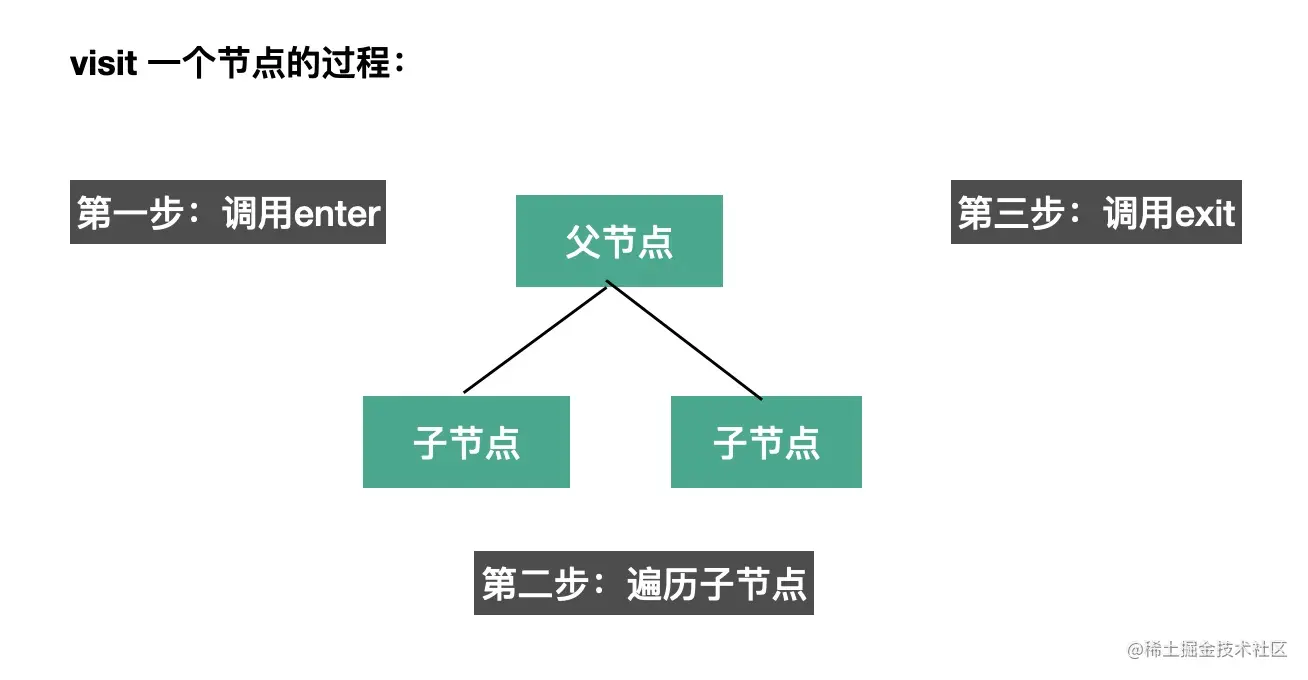
遍历过程
visitor 是指定对什么 AST 做什么处理的函数,babel 会在遍历到对应的 AST 时回调它们。
而且可以指定刚开始遍历(enter)和遍历结束后(exit)两个阶段的回调函数,
比如:
traverse(ast, {
FunctionDeclaration: {
enter(path, state) {}, // 进入节点时调用
exit(path, state) {} // 离开节点时调用
}
})
如果只指定了一个函数,那就是 enter 阶段会调用的:
traverse(ast, {
FunctionDeclaration(path, state) {} // 进入节点时调用
})
enter 时调用是在遍历当前节点的子节点前调用,exit 时调用是遍历完当前节点的子节点后调用。
而且同一个 visitor 函数可以用于多个 AST 节点的处理,方式是指定一系列 AST,用 | 连接
// 进入 FunctionDeclaration 和 VariableDeclaration 节点时调用
traverse(ast, {
'FunctionDeclaration|VariableDeclaration'(path, state) {}
})
此外,AST 还有别名的,比如各种 XxxStatement 有个 Statement 的别名,各种 XxxDeclaration 有个 Declaration 的别名,那自然可以通过别名来指定对这些 AST 的处理:
// 通过别名指定离开各种 Declaration 节点时调用
traverse(ast, {
Declaration: {
exit(path, state) {}
}
})
具体的别名有哪些在babel-types 的类型定义可以查。
每个 visitor 都有 path 和 state 的参数,这些是干啥的呢?
path
AST 是棵树,遍历过程中肯定是有个路径的,path 就记录了这个路径:
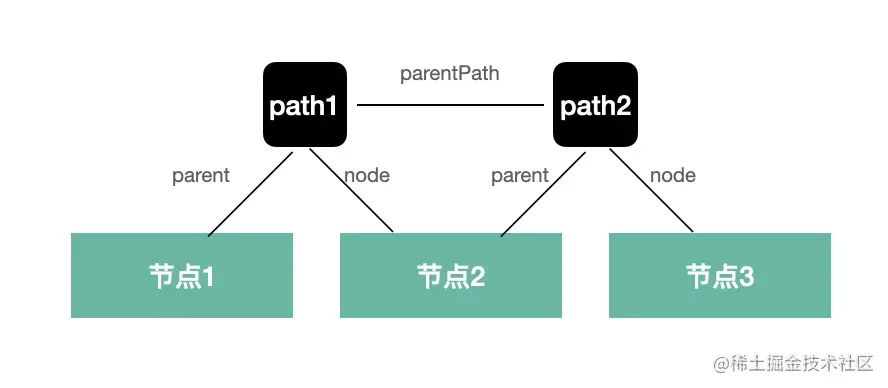
如图,节点 1、节点 2、节点 3 是三层 AST,通过两个 path 关联了起来,
path1 就关联了节点 1 和 节点 2,记录了节点 1 是父节点,节点 2 是子节点。
path2 关联了节点 2 和节点 3,记录了节点 2 是父节点,节点 3 是子节点。
而且 path1 和 path2 还有父子关系。
通过这样的 path 对象,就把遍历的路径串联起来。
而且,最重要的是 path 有很多属性和方法,比如记录父子、兄弟等关系的:
- path.node 指向当前 AST 节点
- path.parent 指向父级 AST 节点
- path.getSibling、path.getNextSibling、path.getPrevSibling 获取兄弟节点
- path.find 从当前节点向上查找节点
- path.get、path.set 获取 / 设置属性的 path
还有作用域相关的:
- path.scope 获取当前节点的作用域信息
判断 AST 类型的:
- path.isXxx 判断当前节点是不是 xx 类型
- path.assertXxx 判断当前节点是不是 xx 类型,不是则抛出异常
增删改 AST 的:
- path.insertBefore、path.insertAfter 插入节点
- path.replaceWith、path.replaceWithMultiple、replaceWithSourceString 替换节点
- path.remove 删除节点
跳过遍历的:
- path.skip 跳过当前节点的子节点的遍历
- path.stop 结束后续遍历
可以增删改 AST,可以按照路径查找任意的节点,还有作用域的信息,那怎么转换和分析代码不就呼之欲出了么。
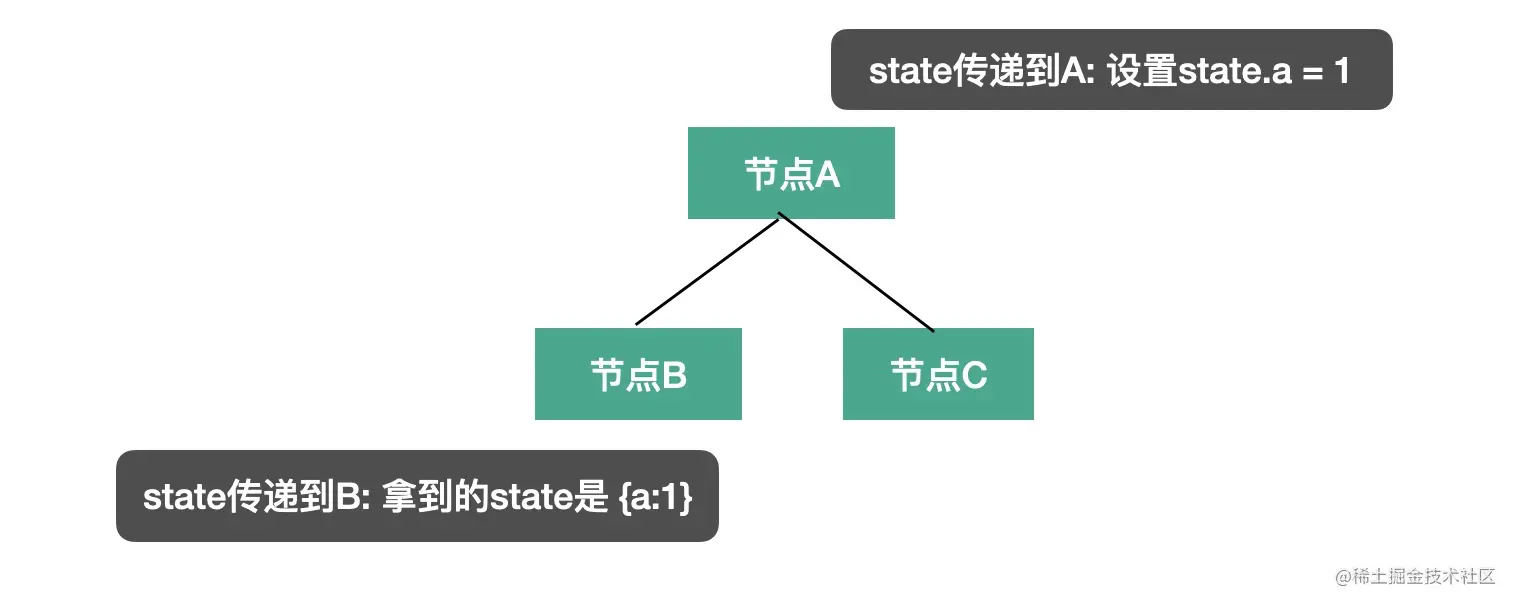
state
第二个参数 state 则是遍历过程中在不同节点之间传递数据的机制,插件会通过 state 传递 options 和 file 信息,我们也可以通过 state 存储一些遍历过程中的共享数据。
@babel/types
遍历 AST 的过程中需要创建一些 AST 和判断 AST 的类型,这时候就需要 @babel/types 包。
举例来说,如果要创建IfStatement就可以调用
t.ifStatement(test, consequent, alternate);
而判断节点是否是 IfStatement 就可以调用 isIfStatement 或者 assertIfStatement
t.isIfStatement(node, opts);
t.assertIfStatement(node, opts);
opts 可以指定一些属性是什么值,增加更多限制条件,做更精确的判断。
t.isIdentifier(node, { name: "paths" })
isXxx 和 assertXxx 看起来很像,但是功能不大一样:isXxx 会返回 boolean,而 assertXxx 则会在类型不一致时抛异常。
@babel/template
通过 @babel/types 创建 AST 还是比较麻烦的,要一个个的创建然后组装,如果 AST 节点比较多的话需要写很多代码,这时候就可以使用 @babel/template 包来批量创建。
这个包有这些 api:
const ast = template(code, [opts])(args);
const ast = template.ast(code, [opts]);
const ast = template.program(code, [opts]);
这些都是传入一段字符串,返回创建好的 AST,区别只是返回的 AST 粒度不大一样:
template.ast 返回的是整个 AST。
template.program 返回的是 Program 根节点。
template.expression 返回创建的 expression 的 AST。
template.statements 返回创建的 statems 数组的 AST。
@babel/generator
AST 转换完之后就要打印成目标代码字符串,通过 @babel/generator 包的 generate api
function (ast: Object, opts: Object, code: string): {code, map}
第一个参数是要打印的 AST。
第二个参数是 options,指定打印的一些细节,比如通过 comments 指定是否包含注释,通过 minified 指定是否包含空白字符。
第三个参数当多个文件合并打印的时候需要用到,这部分直接看文档即可,基本用不到。
options 中常用的是 sourceMaps,开启了这个选项才会生成 sourcemap。
import generate from "@babel/generator";
const { code, map } = generate(ast, { sourceMaps: true })
@babel/code-frame
babel 的报错一半都会直接打印错误位置的代码,而且还能高亮,
我们打印错误信息的时候也可以用,就是 @babel/code-frame 这个包。
const result = codeFrameColumns(rawLines, location, {
/* options */
});
options 可以设置 highlighted (是否高亮)、message(展示啥错误信息)。
比如
const { codeFrameColumns } = require("@babel/code-frame");
try {
throw new Error("xxx 错误");
} catch (err) {
console.error(codeFrameColumns(`const name = guang`, {
start: { line: 1, column: 14 }
}, {
highlightCode: true,
message: err.message
}));
}
打印的错误就是这样的: 
@babel/core
前面讲了 @babel/parser、@babel/traverse、@babel/generaotr、@babel/types、@babel/template 等包,babel 的功能就是通过这些包来实现的。
babel 基于这些包来实现编译、插件、预设等功能的包就是 @babel/core。
这个包的功能就是完成整个编译流程,从源码到目标代码,生成 sourcemap。实现 plugin 和 preset 的调用。
api 也有好几个:
transformSync(code, options); // => { code, map, ast }
transformFileSync(filename, options); // => { code, map, ast }
transformFromAstSync(
parsedAst,
sourceCode,
options
); // => { code, map, ast }
比如这三个 transformXxx 的 api 分别是从源代码、源代码文件、源代码 AST 开始处理,最终生成目标代码和 sourcemap。
options 主要配置 plugins 和 presets,指定具体要做什么转换。
这些 api 也同样提供了异步的版本,异步地进行编译,返回一个 promise
transformAsync("code();", options).then(result => {})
transformFileAsync("filename.js", options).then(result => {})
transformFromAstAsync(parsedAst, sourceCode, options).then(result => {})
WARNING
不带 sync、async 的 api 已经被标记过时了,也就是 transformXxx 这些,后续会删掉,不建议用,直接用 transformXxxSync 和 transformXxxAsync。也就是明确是同步还是异步。
实战案例:插入函数调用参数
需求描述
我们经常会打印一些日志来辅助调试,但是有的时候会不知道日志是在哪个地方打印的。希望通过 babel 能够自动在 console.log 等 api 中插入文件名和行列号的参数,方便定位到代码。
也就是把这段代码:
console.log(1);
转换为这样:
console.log('文件名(行号,列号):', 1);
思路分析
函数调用表达式的 AST 是 CallExpression。
那我们要做的是在遍历 AST 的时候对 console.log、console.info 等 api 自动插入一些参数,也就是要通过 visitor 指定对 CallExpression 的 AST 做一些修改。
CallExrpession 节点有两个属性,callee 和 arguments,分别对应调用的函数名和参数, 所以我们要判断当 callee 是 console.xx 时,在 arguments 的数组中中插入一个 AST 节点。
代码实现
初步实现
import * as parser from "@babel/parser";
import _traverse from "@babel/traverse";
import _generate from "@babel/generator";
import types from '@babel/types';
const traverse = _traverse.default;
const generate = _generate.default;
const sourceCode = `console.log(1)`;
const ast = parser.parse(sourceCode, {
sourceType: 'unambiguous'
});
traverse(ast, {
CallExpression(path) {
if (types.isMemberExpression(path.node.callee)
&& path.node.callee.object.name === 'console'
&& ['log', 'warn', 'info', 'error', 'debug'].includes(path.node.callee.property.name)
) {
const { column, line } = path.node.loc.start;
path.node.arguments.unshift(types.stringLiteral(`filename:(${line},${column})`));
}
}
});
const { code, map } = generate(ast,{ sourceMaps: true });
console.log(code, map);
// console.log("filename:(1,0)", 1); {
// version: 3,
// file: undefined,
// names: [],
// sourceRoot: undefined,
// sources: [],
// sourcesContent: [],
// mappings: ''
// }
优化
现在判断条件比较复杂,要先判断 path.node.callee 的类型,然后一层层取属性来判断,其实我们可以用 generator 模块来简化.
import * as parser from "@babel/parser";
import _traverse from "@babel/traverse";
import _generate from "@babel/generator";
import types from '@babel/types';
const traverse = _traverse.default;
const generate = _generate.default;
const sourceCode = `console.log(1)`;
const ast = parser.parse(sourceCode, {
sourceType: 'unambiguous',
});
const targetCalleeName = ['log', 'info', 'error', 'debug'].map(item => `console.${item}`);
traverse(ast, {
CallExpression(path, state) {
const calleeName = generate(path.node.callee).code;
if (targetCalleeName.includes(calleeName)) {
const { line, column } = path.node.loc.start;
path.node.arguments.unshift(types.stringLiteral(`filename: (${line}, ${column})`))
}
}
});
需求变更
在同一行打印会影响原本的参数的展示,所以想改为在 console.xx 节点之前打印的方式
比如之前是
console.log(1);
转换为
console.log('文件名(行号,列号):', 1);
现在希望转换为:
console.log('文件名(行号,列号):');
console.log(1);
需求变更-思路分析
这个需求的改动只是从插入一个参数变成了在当前 console.xx 的 AST 之前插入一个 console.log 的 AST,整体流程还是一样。
这里有两个注意的点:
JSX 中的 console 代码不能简单的在前面插入一个节点,而要把整体替换成一个数组表达式,因为 JSX 中只支持写单个表达式。
也就是
js<div>{console.log(111)}</div>要替换成数组的形式
js<div>{[console.log('filename.js(11,22)'), console.log(111)]}</div>因为 {} 里只能是表达式,这个 AST 叫做 JSXExpressionContainer,表达式容器。
用新的节点替换了旧的节点之后,插入的节点也是 console.log,也会进行处理,这是没必要的,所以要跳过新生成的节点的处理。
需求变更-代码实现
import * as parser from '@babel/parser';
import _traverse from '@babel/traverse';
import _generate from '@babel/generator';
import _template from '@babel/template';
import types from '@babel/types';
const traverse = _traverse.default;
const generate = _generate.default;
const template = _template.default;
// const sourceCode = `console.log(1)`;
const sourceCode = `<div>{console.log(111)}</div>`;
const ast = parser.parse(sourceCode, {
sourceType: 'unambiguous',
plugins: ['jsx'],
});
const targetCalleeName = ['log', 'info', 'error', 'debug'].map(
(item) => `console.${item}`,
);
traverse(ast, {
CallExpression(path) {
if (path.node._skip) return;
const calleeName = generate(path.node.callee).code;
if (targetCalleeName.includes(calleeName)) {
const { line, column } = path.node.loc.start;
const newNode = template.expression(
`console.log("filename: (${line}, ${column})")`,
)();
newNode._skip = true;
if (path.findParent((path) => path.isJSXElement())) {
path.replaceWith(types.arrayExpression([newNode, path.node]));
path.skip();
} else {
path.insertBefore(types.expressionStatement(newNode));
}
}
},
});
const { code, map } = generate(ast, { sourceMaps: true });
console.log(code, map);
插件化
函数的第一个参数可以拿到 types、template 等常用包的 api,这样我们就不需要单独引入这些包了。
export default function ({ types, template }) {
const targetCalleeName = ['log', 'info', 'error', 'debug'].map(
(item) => `console.${item}`,
);
return {
visitor: {
CallExpression(path) {
if (path.node._skip) return;
const calleeName = path.get('callee').toString();
if (targetCalleeName.includes(calleeName)) {
const { line, column } = path.node.loc.start;
const newNode = template.expression(
`console.log("filename: (${line}, ${column})")`,
)();
newNode._skip = true;
if (path.findParent((path) => path.isJSXElement())) {
path.replaceWith(
types.arrayExpression([newNode, path.node]),
);
path.skip();
} else {
path.insertBefore(types.expressionStatement(newNode));
}
}
},
},
};
}
traverse 的 path、scope、visitor
visitor 模式
visitor 模式的思想是:当被操作的对象结构比较稳定,而操作对象的逻辑经常变化的时候,通过分离逻辑和对象结构,使得他们能独立扩展。
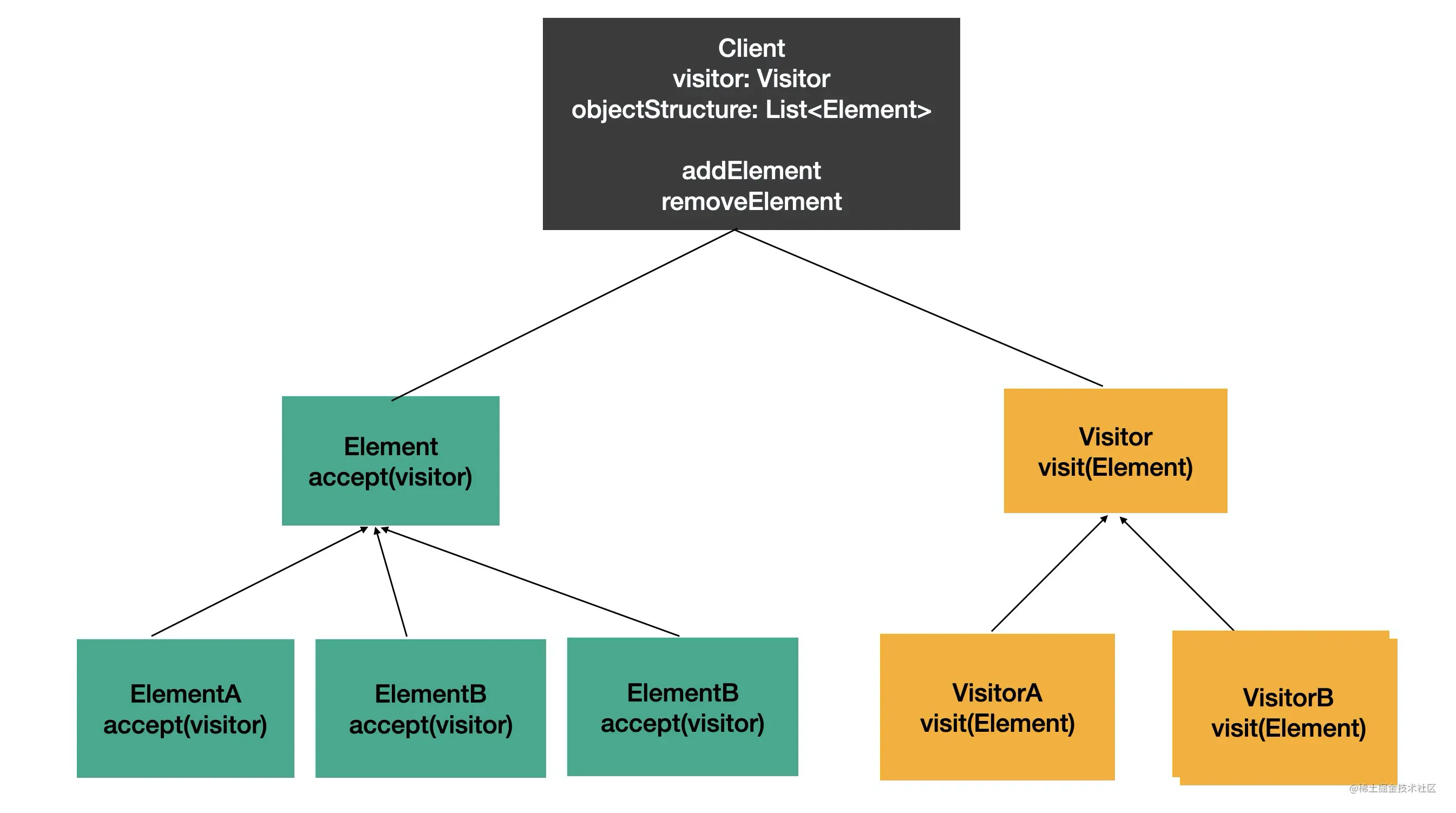
如图,Element 和 Visitor 分别代表对象结构和操作逻辑,两者可以独立扩展,在 Client 里面来组合两者,使用 visitor 操作 element。这就是 visitor 模式。
对应到 babel traverse 的实现,就是 AST 和 visitor 分离,在 traverse(遍历)AST 的时候,调用注册的 visitor 来对其进行处理。
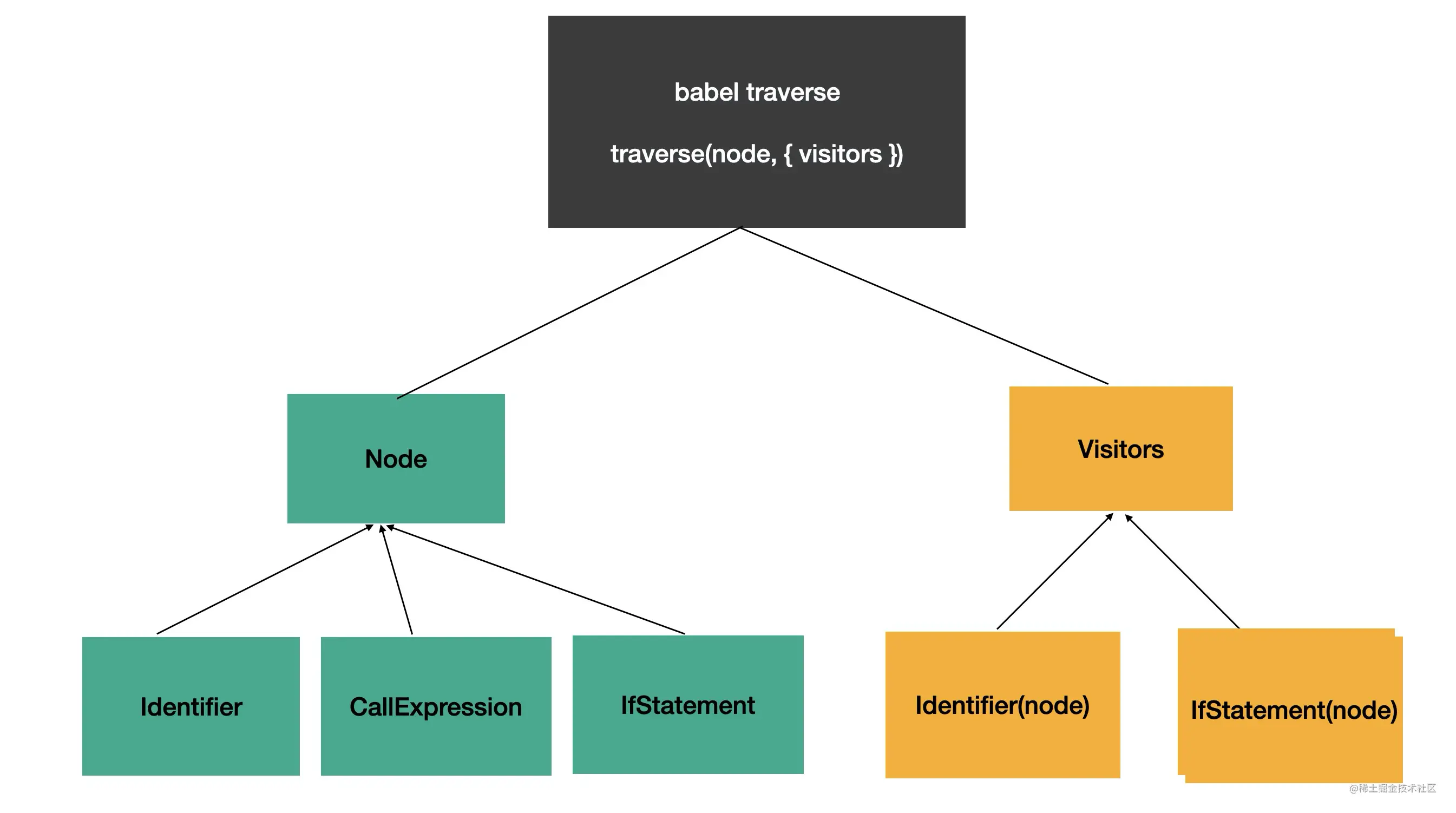
这样 AST 是独立的扩展的,visitor 是独立的扩展的,两者可以各自独立扩展单还能轻易地结合在一起。
path 和 scope
path 是记录遍历路径的 api,它记录了父子节点的引用,还有很多增删改查 AST 的 api:
path
path {
// 属性:
node // 当前 AST 节点
parent // 父 AST 节点
parentPath // 父 AST 节点的 path
scope // 作用域
hub // 可以通过 path.hub.file 拿到最外层 File 对象, path.hub.getScope 拿到最外层作用域,path.hub.getCode 拿到源码字符串
container // 当前 AST 节点所在的父节点属性的属性值
key // 当前 AST 节点所在父节点属性的属性名或所在数组的下标
listKey // 当前 AST 节点所在父节点属性的属性值为数组时 listkey 为该属性名,否则为 undefined
// 方法
get(key)
set(key, node)
inList()
getSibling(key)
getNextSibling()
getPrevSibling()
getAllPrevSiblings()
getAllNextSiblings()
isXxx(opts)
assertXxx(opts)
find(callback)
findParent(callback)
insertBefore(nodes)
insertAfter(nodes)
replaceWith(replacement)
replaceWithMultiple(nodes)
replaceWithSourceString(replacement)
remove()
traverse(visitor, state)
skip()
stop()
}
含义:
- path.node 当前 AST 节点
- path.parent 父 AST 节点
- path.parentPath 父 AST 节点的 path
- path.scope 作用域
- path.hub 可以通过 path.hub.file 拿到最外层 File 对象, path.hub.getScope 拿到最外层作用域,path.hub.getCode 拿到源码字符串
- path.container 当前 AST 节点所在的父节点属性的属性值
- path.key 当前 AST 节点所在父节点属性的属性名或所在数组的下标
- path.listkey 当前 AST 节点所在父节点属性的属性值为数组时 listkey 为该属性名,否则为 undefined
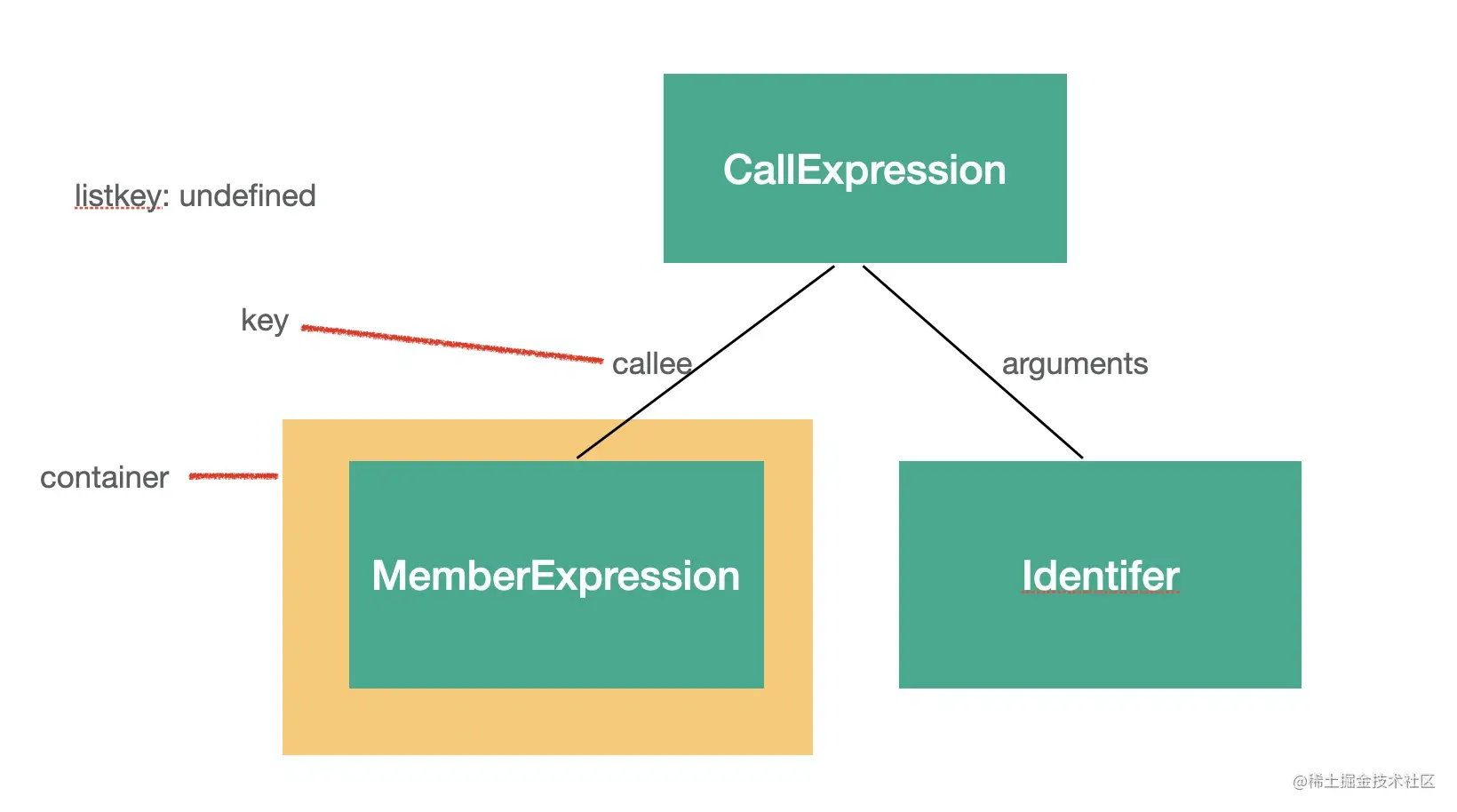
container、listkey、key
因为 AST 节点要挂在父 AST 节点的某个属性上,那个属性的属性值就是这个 AST 节点的 container。
比如 CallExpression 有 callee 和 arguments 属性,那么对于 callee 的 AST 节点来说,callee 的属性值就是它的 container,而 callee 就是它的 key。
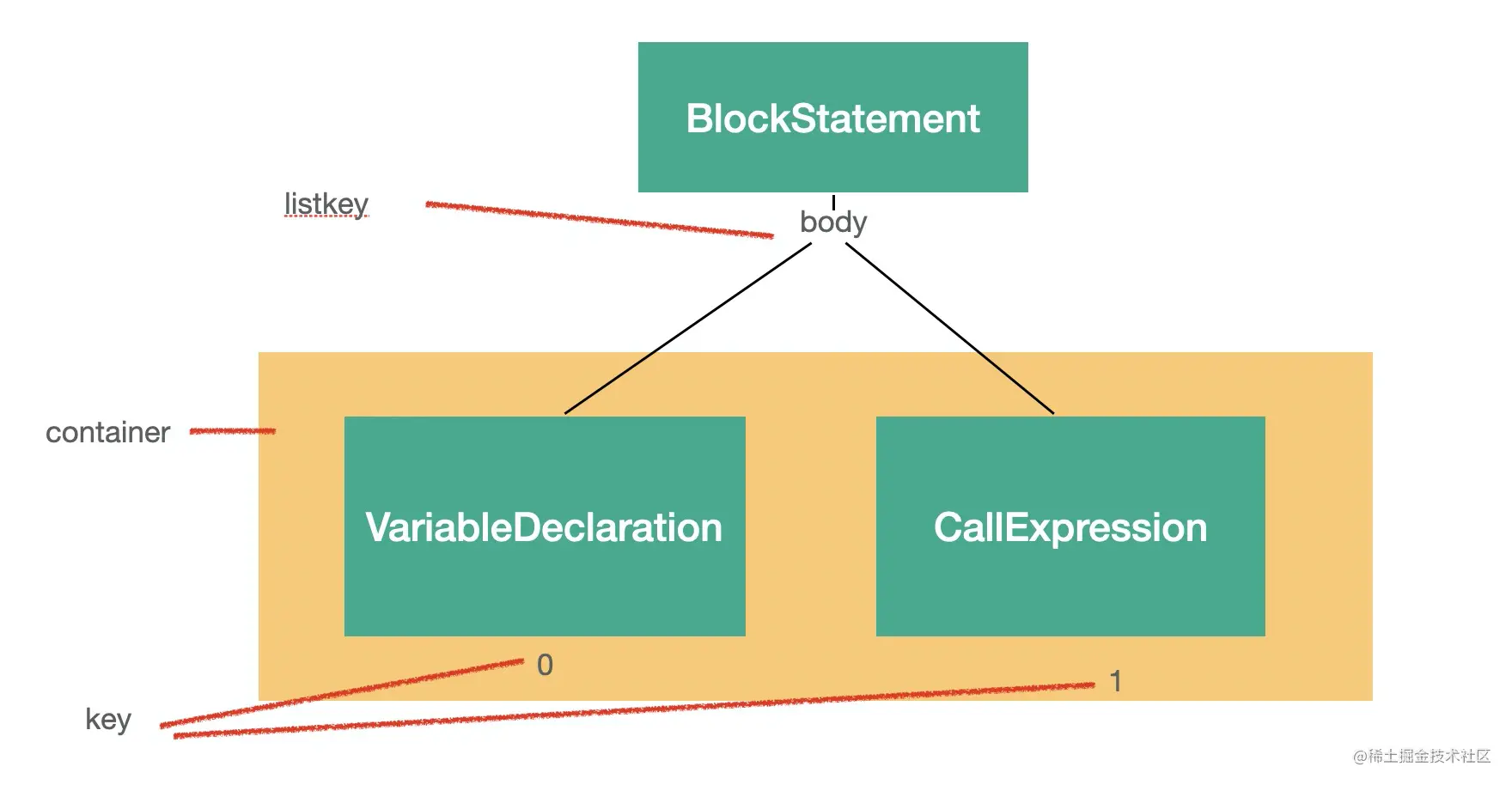
因为不是一个列表,所以 listkey 是 undefined。
而 BlockStatement 有 body 属性,是一个数组,对于数组中的每一个 AST 来说,这个数组就是它们的 container,而 listKey 是 body,key 则是下标。
path 的方法
path 有如下方法,同样也不需要记:
- get(key) 获取某个属性的 path
- set(key, node) 设置某个属性的值
- getSibling(key) 获取某个下标的兄弟节点
- getNextSibling() 获取下一个兄弟节点
- getPrevSibling() 获取上一个兄弟节点
- getAllPrevSiblings() 获取之前的所有兄弟节点
- getAllNextSiblings() 获取之后的所有兄弟节点
- find(callback) 从当前节点到根节点来查找节点(包括当前节点),调用 callback(传入 path)来决定是否终止查找
- findParent(callback) 从当前节点到根节点来查找节点(不包括当前节点),调用 callback(传入 path)来决定是否终止查找
- inList() 判断节点是否在数组中,如果 container 为数组,也就是有 listkey 的时候,返回 true
- isXxx(opts) 判断当前节点是否是某个类型,可以传入属性和属性值进一步判断,比如path.isIdentifier({name: 'a'})
- assertXxx(opts) 同 isXxx,但是不返回布尔值,而是抛出异常
- insertBefore(nodes) 在之前插入节点,可以是单个节点或者节点数组
- insertAfter(nodes) 在之后插入节点,可以是单个节点或者节点数组
- replaceWith(replacement) 用某个节点替换当前节点
- replaceWithMultiple(nodes) 用多个节点替换当前节点
- replaceWithSourceString(replacement) 解析源码成 AST,然后替换当前节点
- remove() 删除当前节点
- traverse(visitor, state) 遍历当前节点的子节点,传入 visitor 和 state(state 是不同节点间传递数据的方式)
- skip() 跳过当前节点的子节点的遍历
- stop() 结束所有遍历
作用域 path.scope
scope 是作用域信息,javascript 中能生成作用域的就是模块、函数、块等,而且作用域之间会形成嵌套关系,也就是作用域链。babel 在遍历的过程中会生成作用域链保存在 path.scope 中。
path.scope {
bindings
block
parent
parentBlock
path
references
dump()
parentBlock()
getAllBindings()
getBinding(name)
hasBinding(name)
getOwnBinding(name)
parentHasBinding(name)
removeBinding(name)
moveBindingTo(name, scope)
generateUid(name)
}
各自的含义:
- scope.bindings 当前作用域内声明的所有变量
- scope.block 生成作用域的 block,详见下文
- scope.path 生成作用域的节点对应的 path
- scope.references 所有 binding 的引用对应的 path,详见下文
- scope.dump() 打印作用域链的所有 binding 到控制台
- scope.parentBlock() 父级作用域的 block
- getAllBindings() 从当前作用域到根作用域的所有 binding 的合并
- getBinding(name) 查找某个 binding,从当前作用域一直查找到根作用域
- getOwnBinding(name) 从当前作用域查找 binding
- parentHasBinding(name, noGlobals) 查找某个 binding,从父作用域查到根作用域,不包括当前作用域。可以通过 noGlobals 参数指定是否算上全局变量(比如console,不需要声明就可用),默认是 false
- removeBinding(name) 删除某个 binding
- hasBinding(name, noGlobals) 从当前作用域查找 binding,可以指定是否算上全局变量,默认是 false
- moveBindingTo(name, scope) 把当前作用域中的某个 binding 移动到其他作用域
- generateUid(name) 生成作用域内唯一的名字,根据 name 添加下划线,比如 name 为 a,会尝试生成 _a,如果被占用就会生成 __a,直到生成没有被使用的名字。
scope.block
能形成 scope 的有这些节点,这些节点也叫 block 节点。
export type Scopable =
| BlockStatement
| CatchClause
| DoWhileStatement
| ForInStatement
| ForStatement
| FunctionDeclaration
| FunctionExpression
| Program
| ObjectMethod
| SwitchStatement
| WhileStatement
| ArrowFunctionExpression
| ClassExpression
| ClassDeclaration
| ForOfStatement
| ClassMethod
| ClassPrivateMethod
| StaticBlock
| TSModuleBlock;
我们可以通过 path.scope.block 来拿到所在的块对应的节点,通过 path.scope.parentBlock 拿到父作用域对应的块节点。
一般情况下我们不需要拿到生成作用域的块节点,只需要通过 path.scope 拿到作用域的信息,通过 path.scope.parent 拿到父作用域的信息。
scope.bindings、scope.references(重点)
作用域中保存的是声明的变量和对应的值,每一个声明叫做一个binding。
比如这样一段代码
const a = 1;
它的 path.scope.bindings 是这样的
bindings: {
a: {
constant: true,
constantViolations: [],
identifier: {type: 'Identifier', ...}
kind:'const',
path: {node,...}
referenced: false
referencePaths: [],
references: 0,
scope: ...
}
}
因为我们在当前 scope 中声明了 a 这个变量,所以 bindings 中有 a 的 binding,每一个 binding 都有 kind,这代表绑定的类型:
- var、let、const 分别代表 var、let、const 形式声明的变量
- param 代表参数的声明
- module 代表 import 的变量的声明
binding 有多种 kind,代表变量是用不同的方式声明的。
binding.identifier 和 binding.path,分别代表标识符、整个声明语句。
声明之后的变量会被引用和修改,binding.referenced 代表声明的变量是否被引用,binding.constant 代表变量是否被修改过。如果被引用了,就可以通过 binding.referencePaths 拿到所有引用的语句的 path。如果被修改了,可以通过 binding.constViolations 拿到所有修改的语句的 path。
path 的 api 还是比较多的,这也是 babel 最强大的地方。主要是操作当前节点、当前节点的父节点、兄弟节点,作用域,以及增删改的方法。
state
state 是遍历过程中 AST 节点之间传递数据的方式。插件的 visitor 中,第一个参数是 path,第二个参数就是 state。
插件可以从 state 中拿到 opts,也就是插件的配置项,也可以拿到 file 对象,file 中有一些文件级别的信息,这个也可以从 path.hub.file 中拿。
state {
file
opts
}
可以在遍历的过程中在 state 中存一些状态信息,用于后续的 AST 处理。
AST 的别名
遍历的时候要指定 visitor 处理的 AST,有的时候需要对多个节点做同样的处理,babel 支持指定多个 AST 类型,也可以通过别名指定一系列类型。
// 单个 AST 类型
FunctionDeclaration(path, state) {},
// 多个 AST 类型
'FunctionDeclaration|VariableDeclaration'(path, state) {}
// AST 类型别名
Declaration(){}
可以在文档中查到某个 AST 类型的别名是啥,某个别名都包含哪些 AST 类型可以在babel-types的类型定义处查。
可以把 @babel/types 源码下载下来看,类型定义在 src/ast-types/generated 目录下,这样可以利用 ide 的功能方便的查看每种 alias 的具体 AST 类型。
所有的 AST 相关的信息都可以在babel-types里查看,每一个 AST 节点怎么创建、怎么校验、怎么遍历,其实都与 AST 的结构有关系,这些都在 babel-types 里面定义。
比如 if 就定义了有哪些属性可以遍历、别名是什么,每一个属性怎么校验,然后会根据这些规则生成xxx,isXxx,assertXxx等api用于创建、判断AST节点。
Generaotr 和 SourceMap 的奥秘
generate
generate 是把 AST 打印成字符串,是一个从根节点递归打印的过程,对不同的 AST 节点做不同的处理,在这个过程中把抽象语法树中省略掉的一些分隔符重新加回来。
比如 while 语句 WhileStatement 就是先打印 while,然后打印一个空格和 '(',然后打印 node.test 属性的节点,然后打印 ')',之后打印 block 部分

比如条件表达式 ConditionExpression 就是分别打印 node.test、node.consequent、node.alternate 属性,中间插入 ? : 和空格。

通过这样的方式递归打印整个 AST,就可以生成目标代码。
@babel/generator 的 src/generators 下定义了每一种AST节点的打印方式
sourcemap
在 generate 的时候选择是否生成 sourcemap,那为什么要生成 sourcemap 呢?
sourcemap 的作用
babel 对源码进行了修改,生成的目标代码可能改动很大,如果直接调试目标代码,那么可能很难对应到源码里。所以需要一种自动关联源码的方式,就是 sourcemap。
我们平时用 sourcemap 主要用两个目的:
调试代码时定位到源码
chrome、firefox 等浏览器支持在文件末尾加上
//# sourceMappingURL=http://example.com/path/to/your/sourcemap.map
可以通过 url 的方式或者转成 base64 内联的方式来关联 sourcemap。调试工具(浏览器、vscode 等会自动解析 sourcemap,关联到源码。这样打断点、错误堆栈等都会对应到相应源码。
线上报错定位到源码
开发时会使用 sourcemap 来调试,但是生产可不会,要是把 sourcemap 传到生产算是大事故了。但是线上报错的时候确实也需要定位到源码,这种情况一般都是单独上传 sourcemap 到错误收集平台。
平时我们至少在这两个场景(开发时调试源码,生产时定位错误)下会用到 sourcemap。
sourcemap的格式
{
version : 3,
file: "out.js",
sourceRoot : "",
sources: ["foo.js", "bar.js"],
names: ["src", "maps", "are", "fun"],
mappings: "AAgBC,SAAQ,CAAEA"
}
比如上面就是一个 sourcemap 文件,对应字段的含义如下:
version:source map的版本,目前为3。
file:转换后的文件名。
sourceRoot:转换前的文件所在的目录。如果与转换前的文件在同一目录,该项为空。
sources:转换前的文件。该项是一个数组,因为可能是多个源文件合并成一个目标文件。
names:转换前的所有变量名和属性名,把所有变量名提取出来,下面的 mapping 直接使用下标引用,可以减少体积。
mappings:转换前代码和转换后代码的映射关系的集合,用分号代表一行,每行的 mapping 用逗号分隔。
重点看 mappping 部分
mappings:"AAAAA,BBBBB;;;;CCCCC,DDDDD"
每一个分号 ; 表示一行,多个空行就是多个 ;,mapping 通过 , 分割。
mapping有五位:
第一位是目标代码中的列数
第二位是源码所在的文件名
第三位是源码对应的行数
第四位是源码对应的列数
第五位是源码对应的 names,不一定有
每一位是通过 VLQ 编码的,一个字符就能表示行列数
sourcemap 通过 names 和 ; 的设计省略掉了一些变量名和行数所占的空间,又通过 VLQ 编码使得一个字符就可以表示行列数等信息。通过不大的空间占用完成了源码到目标代码的映射。
那么 sourcemap 的源码和目标代码的行列数是怎么来的呢?
其实我们在 parse 的时候就在 AST 节点中保存了 loc 属性,这就是源码中的行列号,在后面 transform 的过程中,并不会去修改它,所以转换完以后节点中仍然保留有源码中的行列号信息,在 generate 打印成目标代码的时候会计算出新的行列号,这样两者关联就可以生成 sourcemap。
具体生成 sourcemap 的过程是用 mozilla 维护的 source-map 这个包,其他工具做 sourcemap 的解析和生成也是基于这个包。
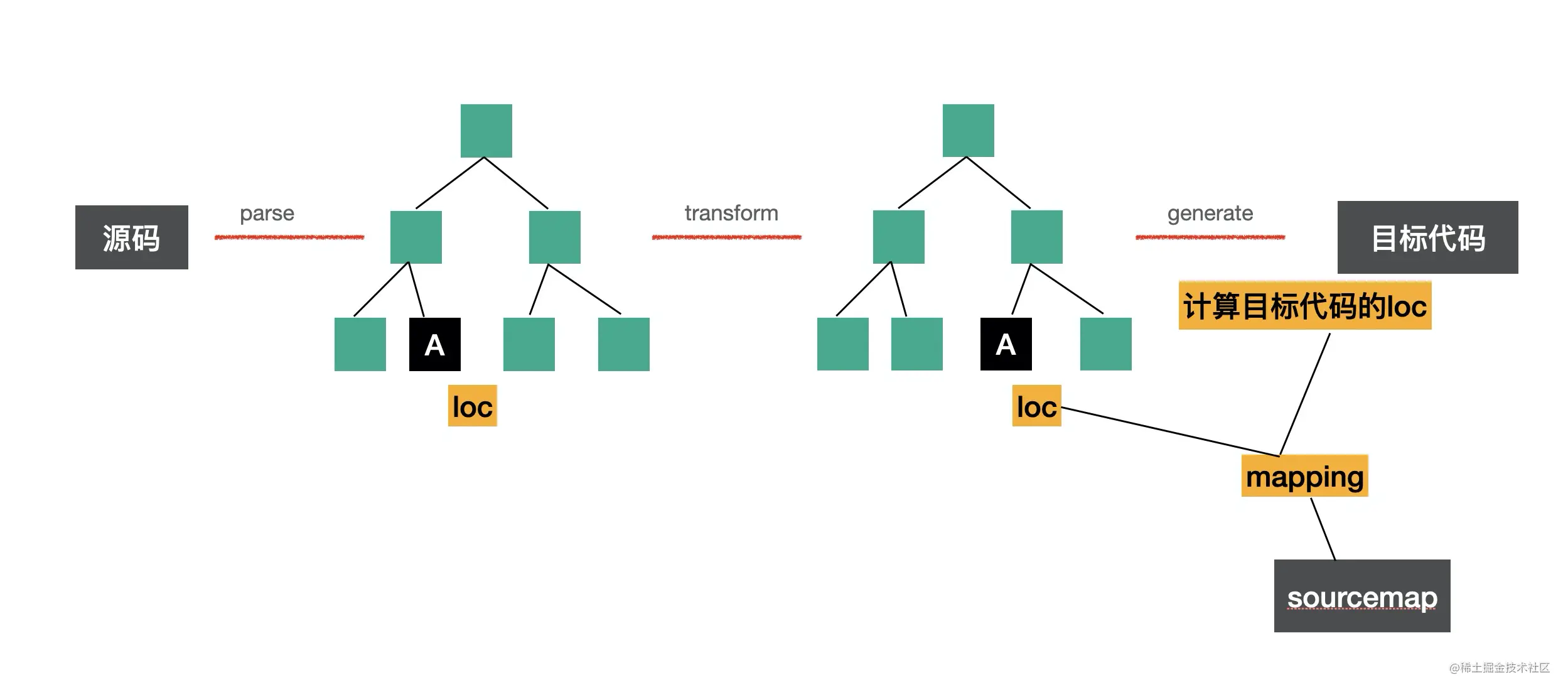
soruce-map
source-map 可以用于生成和解析 sourcemap,需要手动操作 sourcemap 的时候可以用。我们通过它的 api 来感受下 babel 是怎么生成 sourcemap 的。
source-map 暴露了 SourceMapConsumer、SourceMapGenerator、SourceNode 3个类,分别用于消费 sourcemap、生成 sourcemap、创建源码节点
生成 sourcemap
生成 sourcemap 的流程是:
- 创建一个 SourceMapGenerator 对象
- 通过 addMapping 方法添加一个映射
- 通过 toString 转为 sourcemap 字符串
var map = new SourceMapGenerator({
file: "source-mapped.js"
});
map.addMapping({
generated: {
line: 10,
column: 35
},
source: "foo.js",
original: {
line: 33,
column: 2
},
name: "christopher"
});
console.log(map.toString());
// '{"version":3,"file":"source-mapped.js",
// "sources":["foo.js"],"names":["christopher"],"mappings":";;;;;;;;;mCAgCEA"}'
消费 sourcemap
SourceMapConsumer.with 的回调里面可以拿到 consumer 的 api,调用 originalPositionFor 和 generatedPositionFor 可以分别用目标代码位置查源码位置和用源码位置查目标代码位置。还可以通过 eachMapping 遍历所有 mapping,对每个进行处理。
const rawSourceMap = {
version: 3,
file: "min.js",
names: ["bar", "baz", "n"],
sources: ["one.js", "two.js"],
sourceRoot: "http://example.com/www/js/",
mappings: "CAAC,IAAI,IAAM,SAAUA,GAClB,OAAOC,IAAID;CCDb,IAAI,IAAM,SAAUE,GAClB,OAAOA"
};
const whatever = await SourceMapConsumer.with(rawSourceMap, null, consumer => {
// 目标代码位置查询源码位置
consumer.originalPositionFor({
line: 2,
column: 28
})
// { source: 'http://example.com/www/js/two.js',
// line: 2,
// column: 10,
// name: 'n' }
// 源码位置查询目标代码位置
consumer.generatedPositionFor({
source: "http://example.com/www/js/two.js",
line: 2,
column: 10
})
// { line: 2, column: 28 }
// 遍历 mapping
consumer.eachMapping(function(m) {
// ...
});
return computeWhatever();
});
Code-Frame 和代码高亮原理
当代码运行报错时,我们会打印错误,错误中有堆栈信息,可以定位到对应的代码位置。但有的时候我们希望能够更直接准确的打印报错位置的代码。比如这样:

这种错误信息是不是感觉很常见?
这叫做 code frame。
这个可以使用 @babel/code-frames 来打印:
const { codeFrameColumns } = require('@babel/code-frame');
const res = codeFrameColumns(code, {
start: { line: 2, column: 1 },
end: { line: 3, column: 5 },
}, {
highlightCode: true,
message: '这里出错了'
});
console.log(res);
当然,也可以直接使用 path.buildCodeFrameError(path, options) 来创建这种错误信息。
注意,这里的代码高亮是在控制台实现的,不能用网页里的那种库。
那么它是怎么做到的打印出上面的 code frame 的代码格式的呢?
这节我们就来探究下原理。
核心就是这三个问题:
- 如何打印出标记相应位置代码的 code frame(就是上图的打印格式)
- 如何实现语法高亮
- 如何在控制台打印颜色
如何打印 code frame
我们先不管高亮,实现这样的格式的打印:
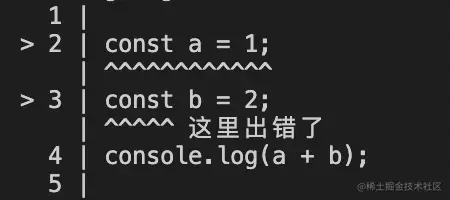
其实就是一个拼接字符串的过程,下面是拼接字符串的细节(了解即可):
传入了源代码、标记开始和结束的行列号,那么我们就能够计算出显示标记(marker ">")的行是哪些,以及这些行的哪些列,然后依次对每一行代码做处理,如果本行没有标记则保持原样,如果本行有标记的话,那么就在开始打印一个 marker ">",并且在下面打印一行 marker "^",最后一个标记行还要打印错误信息。
我们来看一下 @babel/code-frame 的实现:
首先,分割字符串成每一行的数组,然后根据传入的位置计算出 marker(>) 所在的位置。
比如图中第二行的第 1 到 12 列,第三行的 0 到 5 列。
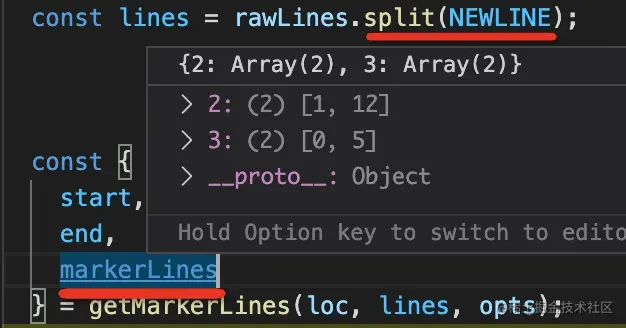
然后对每一行做处理,如果本行有标记,则拼成 marker + gutter(行号) + 代码的格式,下面再打印一行 marker,最后的 marker 行打印 message。没有标记不处理。
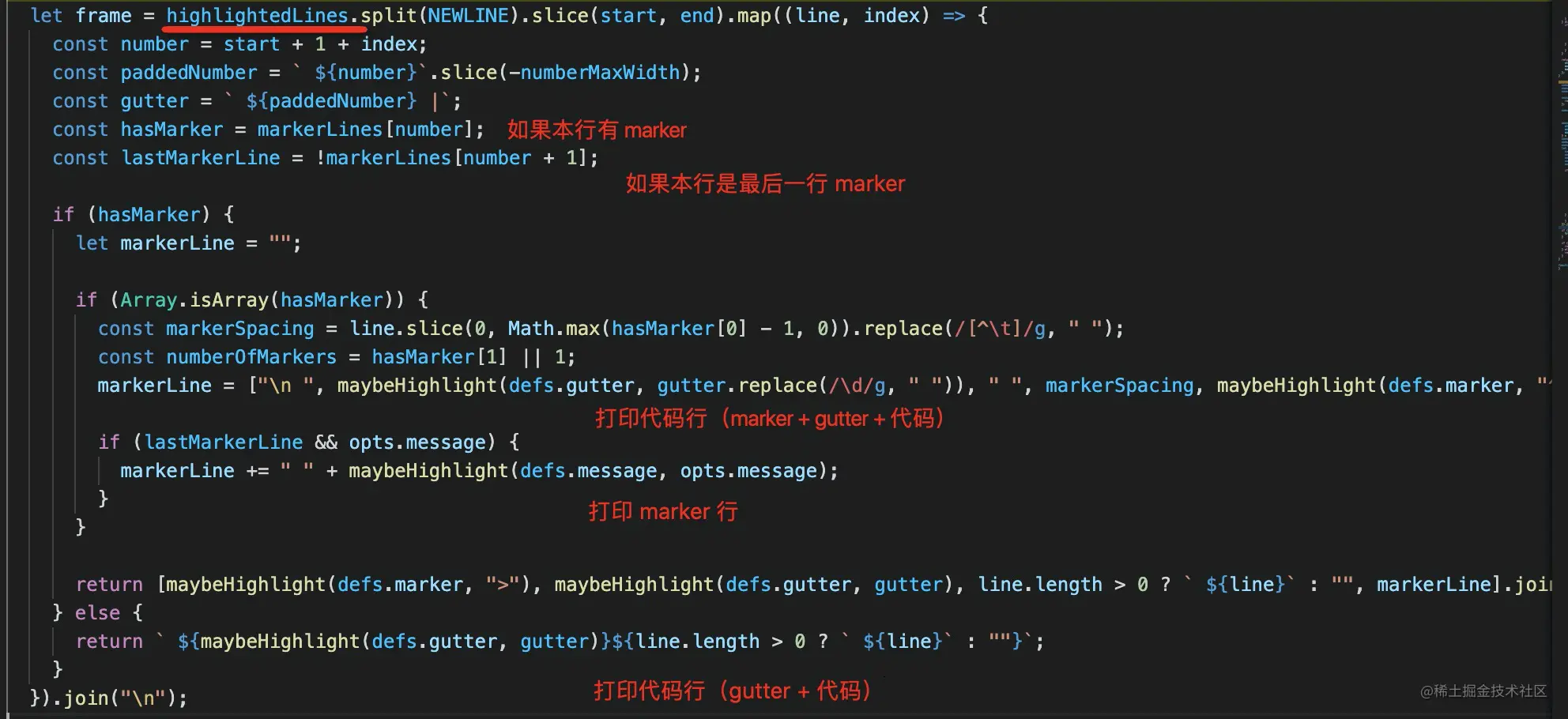
这样最终拼出的就是这样的 code frame:
如何实现语法高亮
实现语法高亮,词法分析就足够了,babel 也是这么做的,@babel/highlight 包里面完成了高亮代码的逻辑。
先看效果:
const a = 1;
const b = 2;
console.log(a + b);
上面的源码被分成了 token 数组:
[
[ 'whitespace', '\n' ], [ 'keyword', 'const' ],
[ 'whitespace', ' ' ], [ 'name', 'a' ],
[ 'whitespace', ' ' ], [ 'punctuator', '=' ],
[ 'whitespace', ' ' ], [ 'number', '1' ],
[ 'punctuator', ';' ], [ 'whitespace', '\n' ],
[ 'keyword', 'const' ], [ 'whitespace', ' ' ],
[ 'name', 'b' ], [ 'whitespace', ' ' ],
[ 'punctuator', '=' ], [ 'whitespace', ' ' ],
[ 'number', '2' ], [ 'punctuator', ';' ],
[ 'whitespace', '\n' ], [ 'name', 'console' ],
[ 'punctuator', '.' ], [ 'name', 'log' ],
[ 'bracket', '(' ], [ 'name', 'a' ],
[ 'whitespace', ' ' ], [ 'punctuator', '+' ],
[ 'whitespace', ' ' ], [ 'name', 'b' ],
[ 'bracket', ')' ], [ 'punctuator', ';' ],
[ 'whitespace', '\n' ]
]
token 怎么分的呢?
一般来说词法分析就是有限状态自动机(DFA),但是这里实现比较简单,是通过正则匹配的:
js-tokens 这个包暴露出来一个正则,一个函数,正则是用来识别 token 的,其中有很多个分组,而函数里面是对不同的分组下标返回了不同的类型,这样就能完成 token 的识别和分类。
在 @babel/highlight 包里基于这个正则来匹配 token
有了分类之后,不同 token 显示不同颜色,建立个 map 就行了。
@babel/highlight 里的实现:

如何在控制台打印颜色
控制台打印的是 ASCII 码,并不是所有的编码都对应可见字符,ASCII 码有一部分字符是对应控制字符的,比如 27 是 ESC,就是我们键盘上的 ESC 键,是 escape 的缩写,按下它可以完成一些控制功能,这里我们可以通过打印 ESC 的 ASCII 码来进入控制打印颜色的状态。
格式是这样的:
ESC [ 前景色 ; 背景色 ; 加粗 ; 下划线 ; m
打印一个 ESC 的 ASCII 码,之后是 [ 代表开始,m 代表结束,中间是用 ; 分隔的 n 个控制字符,可以控制很多样式,比如前景色、背景色、加粗、下划线等等。
ESC 的 ASCII 码是 27,有好几种写法:一种是字符表示的 \e ,一种是 16 进制的 \0x1b(27 对应的 16进制),一种是 8 进制的 \033,这三种都表示 ESC。
我们来试验一下: 1 表示加粗、36 表示前景色为青色、4 表示下划线,下面三种写法等价:
\e[36;1;4m
\033[36;1;4m
\0x1b[36;1;4m

当然,加了样式还要去掉,可以加一个 \e[0m 就可以了(\033[0m,\0x1b[0m 等价)。
chalk(nodejs 的在终端打印颜色的库)的不同方法就是封装了这些 ASCII 码的颜色控制字符。
Babel 插件和 preset
plugin 的使用
babel 的 plugin 是在配置文件里面通过 plugins 选项配置,值为字符串或者数组。
{
"plugins": ["pluginA", ["pluginB"], ["pluginC", {/* options */}]]
}
如果需要传参就用数组格式,第二个元素为参数。
plugin的格式
babel plugin 有两种格式:
返回对象的函数
第一种是一个函数返回一个对象的格式,对象里有 visitor、pre、post、inherits、manipulateOptions 等属性。
export default function(api, options, dirname) {
return {
inherits: parentPlugin,
manipulateOptions(options, parserOptions) {
options.xxx = '';
},
pre(file) {
this.cache = new Map();
},
visitor: {
StringLiteral(path, state) {
this.cache.set(path.node.value, 1);
}
},
post(file) {
console.log(this.cache);
}
};
}
首先,插件函数有 3 个参数,api、options、dirname。
- api 里包含了各种 babel 的 api,比如 types、template 等,这些包就不用在插件里单独单独引入了,直接取来用就行。
- options 就是外面传入的参数
- dirname 是目录名(不常用
返回的对象有 inherits、manipulateOptions、pre、visitor、post 等属性。
- inherits 指定继承某个插件,和当前插件的 options 合并,通过 Object.assign 的方式。
- visitor 指定 traverse 时调用的函数。
- pre 和 post 分别在遍历前后调用,可以做一些插件调用前后的逻辑,比如可以往 file(表示文件的对象,在插件里面通过 state.file 拿到)中放一些东西,在遍历的过程中取出来。
- manipulateOptions 用于修改 options,是在插件里面修改配置的方式
插件做的事情就是通过 api 拿到 types、template 等,通过 state.opts 拿到参数,然后通过 path 来修改 AST。可以通过 state 放一些遍历过程中共享的数据,通过 file 放一些整个插件都能访问到的一些数据,除了这两种之外,还可以通过 this 来传递本对象共享的数据。
对象
插件的第二种格式就是直接写一个对象,不用函数包裹,这种方式用于不需要处理参数的情况。
export default plugin = {
pre(state) {
this.cache = new Map();
},
visitor: {
StringLiteral(path, state) {
this.cache.set(path.node.value, 1);
}
},
post(state) {
console.log(this.cache);
}
};
preset
plugin 是单个转换功能的实现,当 plugin 比较多或者 plugin 的 options 比较多的时候就会导致使用成本升高。这时候可以封装成一个 preset,用户可以通过 preset 来批量引入 plugin 并进行一些配置。preset 就是对 babel 配置的一层封装。
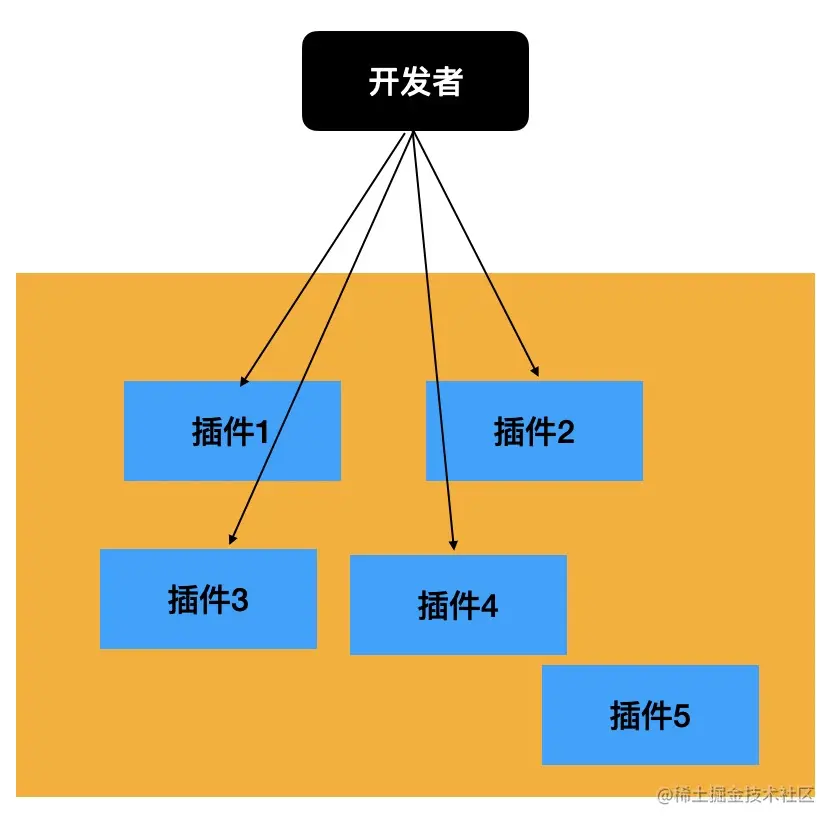
而有了 preset 之后就不再需要知道用到了什么插件,只需要选择合适的 preset,然后配置一下,就会引入需要的插件,这就是 preset 的意义。
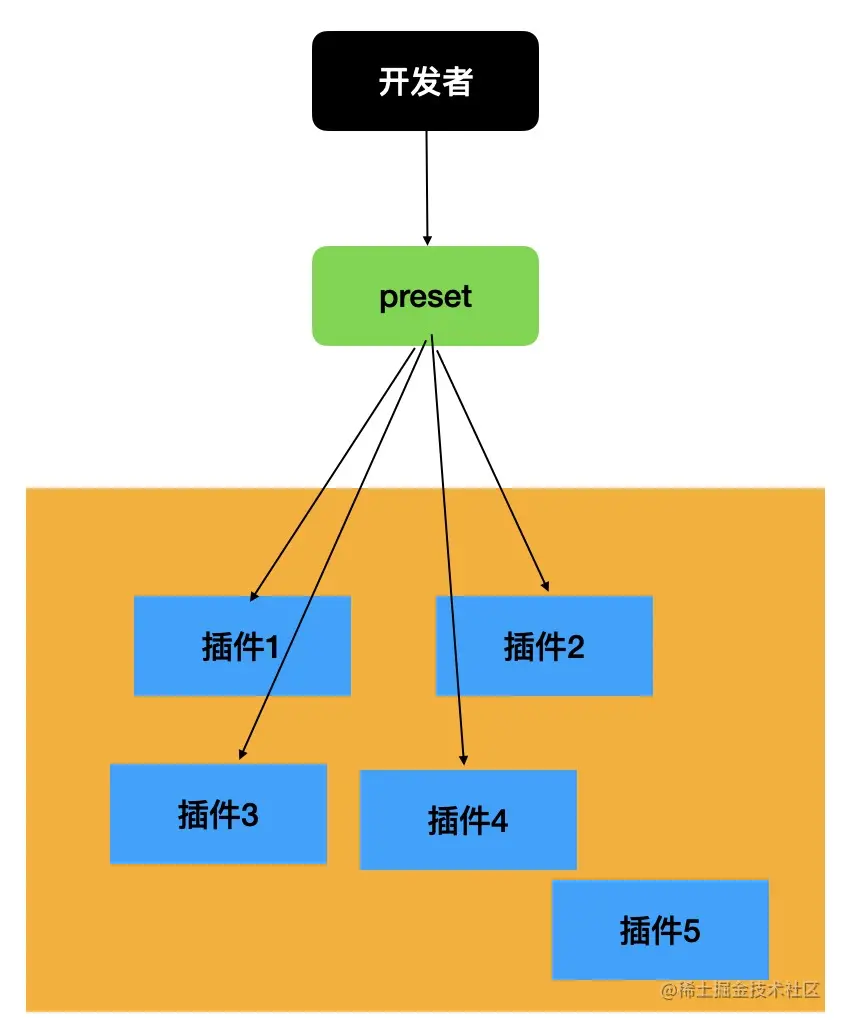
preset 格式和 plugin 一样,也是可以是一个对象,或者是一个函数,函数的参数也是一样的 api 和 options,区别只是 preset 返回的是配置对象,包含 plugins、presets 等配置。
export default function(api, options) {
return {
plugins: ['pluginA'],
presets: [['presetsB', { options: 'bbb'}]]
}
}
export default obj = {
plugins: ['pluginA'],
presets: [['presetsB', { options: 'bbb'}]]
}
ConfigItem
@babel/core 的包提供了 createConfigItem 的 api,用于创建配置项。我们之前都是字面量的方式创建的,当需要把配置抽离出去时,可以使用 createConfigItem。
const pluginA = createConfigItem('pluginA);
const presetB = createConfigItem('presetsB', { options: 'bbb'})
export default obj = {
plugins: [ pluginA ],
presets: [ presetB ]
}
}
顺序
preset 和 plugin 从形式上差不多,但是应用顺序不同。
babel 会按照如下顺序处理插件和 preset:
- 先应用 plugin,再应用 preset
- plugin 从前到后,preset 从后到前
名字
babel 对插件名字的格式有一定的要求,比如最好包含 babel-plugin,如果不包含的话也会自动补充。
babel plugin 名字的补全有这些规则:
- 如果是 ./ 开头的相对路径,不添加 babel plugin,比如 ./dir/plugin.js
- 如果是绝对路径,不添加 babel plugin,比如 /dir/plugin.js
- 如果是单独的名字 aa,会添加为 babel-plugin-aa,所以插件名字可以简写为 aa
- 如果是单独的名字 aa,但以 module 开头,则不添加 babel plugin,比如 module:aa
- 如果 @scope 开头,不包含 plugin,则会添加 babel-plugin,比如 @scope/mod 会变为 @scope/babel-plugin-mod
- babel 自己的 @babel 开头的包,会自动添加 plugin,比如 @babel/aa 会变成 @babel/plugin-aa (preset也是一样)
规则比较多,总结一下就是 babel 希望插件名字中能包含 babel plugin,这样写 plugin 的名字的时候就可以简化,然后 babel 自动去补充。所以我们写的 babel 插件最好是 babel-plugin-xx 和 @scope/babel-plugin-xx 这两种,就可以简单写为 xx 和 @scope/xx。
写 babel 内置的 plugin 和 preset 的时候也可以简化,比如 @babel/preset-env 可以直接写@babel/env,babel 会自动补充为 @babel/preset-env。
Babel 插件的单元测试
babel 插件单元测试的方式
babel 插件做的事情就是对 AST 做转换,可以想到几种测试的方式:
- 测试转换后的 AST,是否符合预期
- 测试转换后生成的代码,是否符合预期(如果代码比较多,可以存成快照,进行快照对比)
- 转换后的代码执行一下,测试是否符合预期
分别对应的代码(使用 jest):
AST测试
这种测试方法就是判断AST 修改的对不对
it('包含guang', () => {
const {ast} = babel.transform(input, {plugins: [plugin]});
const program = ast.program;
const declaration = program.body[0].declarations[0];
assert.equal(declaration.id.name, 'guang');// 判断 AST 节点的值
});
生成代码的快照测试
这种测试方法是每次测试记录下快照,后面之前的对比下:
it('works', () => {
const {code} = babel.transform(input, {plugins: [plugin]});
expect(code).toMatchSnapshot();
});
执行测试
这种测试就是执行下转换后的代码,看执行是否正常:
it('替换baz为foo', () => {
var input = `
var foo = 'guang';
// 把baz重命名为foo
var res = baz;
`;
var {code} = babel.transform(input, {plugins: [plugin]});
var f = new Function(`
${code};
return res;
`);
var res = f();
assert(res === 'guang', 'res is guang');
});
babel-plugin-tester
babel-plugin-tester 就是对比生成的代码的方式来实现的。
可以直接对比输入输出的字符串,也可以对比文件,还可以对比快照:
import pluginTester from 'babel-plugin-tester';
import xxxPlugin from '../xxx-plugin';
pluginTester({
plugin: xxxPlugin,
fixtures: path.join(__dirname, '__fixtures__'), // 保存测试点的地方
tests: {
'case1:xxxxxx': '"hello";', // 输入输出都是同个字符串
'case2:xxxxxx': { // 指定输入输出的字符串
code: 'var hello = "hi";',
output: 'var olleh = "hi";',
},
'case3:xxxxxx': { // 指定输入输出的文件,和真实输出对比
fixture: 'changed.js',
outputFixture: 'changed-output.js',
},
'case4:xxxxxx': { // 指定输入字符串,输出到快照文件中,对比测试
code: `
function sayHi(person) {
return 'Hello ' + person + '!'
}
`,
snapshot: true,
},
},
});
Babel 的内置功能一
插件 --> preset
要实现转换,第一步要明确转换什么: 划定一个集合放要转换的特性,再划定一个集合放转换到的目标特性,两者建立一一映射关系。就确定了我们要做哪些转换。
exponentiation operator
比如乘方运算符,我们会用 Math.pow 来实现
let x = 10 ** 2;
x **= 3;
转换为
let x = Math.pow(10, 2);
x = Math.pow(x, 3);
class
再比如 class,我们会用 function、prototype 来实现
class Test {
constructor(name) {
this.name = name;
}
logger() {
console.log("Hello", this.name);
}
}
转换为
function _classCallCheck(instance, Constructor) {
if (!(instance instanceof Constructor)) {
throw new TypeError("Cannot call a class as a function");
}
}
var Test = (function() {
function Test(name) {
_classCallCheck(this, Test);
this.name = name;
}
Test.prototype.logger = function logger() {
console.log("Hello", this.name);
};
return Test;
})();
每一个语法都可以这样转换为低版本的语法,那把所有的这种高版本语法写的代码转换为低版本的,那不就实现了编译了么。
但是只是转换并不能解决所有问题,涉及到某个对象的 api,比如 Array.prototype.find,这种 api 的兼容并不是需要转换语法,而是要在环境中注入我们实现的 api,也就是 polyfill (垫片)。
所以我们做的事情除了语法转换外,还有 api 的 polyfill。
先说语法转换。
我们要转换哪些语法呢?
babel 插件需要转换的语法包括 es 标准语法、proposal 阶段的语法,还有 react、flow、typescript 等特有语法。
es 标准语法
我们知道,TC39 是制定 javascript 语言标准的组织,每年都会公布加入到语言标准的特性,es2015、es2016、es2017 等。这些是我们要转换的语言特性范围。
在 babel6 时,分别用 preset-es2015、 preset-es2016 等来维护相应的 transform plugin,但在 babel7 的时候就改为 preset env 了。
proposal 阶段的语法
babel 要转换的不只是加入标准的特性,语言特性从提出到标准会有一个过程,分为几个阶段。
- 阶段 0 - Strawman: 只是一个想法,可能用 babel plugin 实现
- 阶段 1 - Proposal: 值得继续的建议
- 阶段 2 - Draft: 建立 spec
- 阶段 3 - Candidate: 完成 spec 并且在浏览器实现
- 阶段 4 - Finished: 会加入到下一年的 es20xx spec
这些还未加入到语言标准的特性也是要支持的。
react、flow、typescript
只是转换 javascript 本身的 es spec 和 proposal 的特性特性并不够,现在我们开发的时候 jsx、typescript、flow 这些都是会用的,babel 肯定也得支持。
这些转换对应的 plugin 分别放在不同 preset 里: preset-jsx、preset-typescript、preset-flow。
我们要转换的范围又大了一些。
上面是插件要转换的语言特性,babel7 内置的实现这些特性的插件分为 syntax、transform、proposal 3类。
syntax plugin
syntax plugin 是在 parserOptions 中放入一个 flag 让 parser 知道要 parse 什么语法,最终的 parse 逻辑还是 babel parser(babylon) 实现的。
一般 syntax plugin 都是这样的:
import { declare } from "@babel/helper-plugin-utils";
export default declare(api => {
api.assertVersion(7);
return {
name: "syntax-function-bind",
manipulateOptions(opts, parserOpts) {
parserOpts.plugins.push("functionBind");
},
};
});
transform plugin
transform plugin 是对 AST 的转换,各种 es20xx 语言特性、typescript、jsx 等的转换都是在 transform plugin 里面实现的。
有的时候需要结合 syntax plugin 和 transform plugin, 比如 typescript 的语法解析要使用 @babel/plugin-syntax-typescript 在 parserOptions 放入解析 typescript 语法的选项,然后使用 @babel/plugin-transform-typescript 来转换解析出的 typescript 对应的 AST 的转换。
平时我们一般使用 @babel/preset-typescript,它对上面两个插件做了封装。
proposal plugin
未加入语言标准的特性的 AST 转换插件叫 proposal plugin,其实他也是 transform plugin,但是为了和标准特性区分,所以这样叫。
完成 proposal 特性的支持,有时同样需要 综合 syntax plugin 和 proposal plugin,比如 function bind (:: 操作符)就需要同时使用 @babel/plugin-syntax-function-bind 和 @babel/plugin-proposal-function-bind。
总之,babel 的内置的 plugin,就 @babel/plugin-syntax-xxx, @babel/plugin-transform-xxx、@babel/plugin-proposal-xxx 3种。
这样的 plugin 还是很多的,所以又设计了 preset。
preset
用于不同的目的需要不同的 babel 插件,所以 babel 设计了 preset
- 不同版本的语言标准支持: preset-es2015、preset-es2016 等,babel7 后用 preset-env 代替
- 未加入标准的语言特性的支持: 用于 stage0、stage1、stage2 的特性,babel7 后单独引入 proposal plugin
- 用于 react、jsx、flow 的支持:分别封装相应的插件为 preset-react、preset-jsx、preset-flow,直接使用对应 preset 即可
- preset 就是插件的集合,但是它可以动态确定包含的插件,比如 preset-env 就是根据 targets 来确定插件。
插件和插件之间自然有一些公共的代码,这部分放在 helper 里:
helper
每个特性的实现用一个 babel 插件实现,当 babel 插件多了,自然会有一些共同的逻辑。这部分逻辑怎么共享呢?
babel 设计了插件之间共享逻辑的机制,就是 helper。
helper 分为两种:
- 一种是注入到 AST 的运行时用的全局函数
- 一种是操作 AST 的工具函数,比如变量提升这种通用逻辑
注入到 AST 的全局函数
注入到 AST 的运行时用的全局函数,比如
class Guang {}
会被转化为
function _classCallCheck(instance, Constructor) {
//...
}
var Guang = function Guang() {
_classCallCheck(this, Guang);
};
这里的 _classCallCheck 就是 helper。
这类 helper 数量比较多,babel7 有 80 多个,都在 @babel/helpers 里面。在插件里使用的话,直接调用 this.addHelper,会在顶层作用域声明对应的 helper,然后返回对应的 identifier。
var transformObjectSetPrototypeOfToAssign = declare(function (api) {
api.assertVersion(7);
return {
name: "transform-object-set-prototype-of-to-assign",
visitor: {
CallExpression: function CallExpression(path) {
if (path.get("callee").matchesPattern("Object.setPrototypeOf")) {
path.node.callee = this.addHelper("defaults");
}
}
}
};
});
其实一般我们也用不到,主要是 babel 内部用的。
这种 helper 是用于用低版本特性实现高版本特性的,比如用 function 和 prototype 实现 class.
内部用 template 实现的:
除了编译的时候注入 helper 以外,runtime 包里也要包含这些 helper。
因为我们可以把 helper 注入到 AST,也可以抽离成从 runtime 包引入的形式:
比如这样:
除了用于注入同样的 AST 的 helper,还有一些公共逻辑的 helper:
操作 AST 的工具函数
操作 AST 的工具函数,比如变量提升自己实现的话还是比较麻烦的,这种通用逻辑可以封装到 helper 里,然后插件里直接用:
const hoistVariables = require('@babel/helper-hoist-variables').default;
cosnt plugin = function () {
visitor: {
VariableDeclaration(path) {
hoistVariables(path.parentPath, (id) => {
path.scope.parent.push({
id: path.scope.generateUidIdentifier(id.name)
});
return id;
}, 'const' );
}
}
}
当输入为
function func(){
const a = 1;
const b = 2;
}
输出为
var _a, _b;
function func() {
a = 1;
b = 2;
}
我们借助 @babel/helper-hoist-variables 轻松实现了变量提升的逻辑。
再举一个例子
const importModule = require('@babel/helper-module-imports');
cosnt plugin = function ({ template }) {
visitor: {
Program(path) {
const reactIdentifier = importModule.addDefault(path, 'lodash',{
nameHint: '_'
});
path.node.body.push(template.ast(`const get = _.get`));
}
}
}
会在代码中加入模块引入和变量声明的代码
var _ = _interopRequireDefault(require("lodash")).default;
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }
const get = _.get;
我们借助 @babel/helper-module-imports 可以很轻松的引入一个模块,通过 named import、default import 或者 namespace import 的方式。
这类 helper 的特点是需要手动引入对应的包,调用 api,而不是直接 this.addHelper 就行。
说了这么多,其实 helper 一般我们也不会用到,知道它是做啥的就行。
babel helpers 是用于 babel plugin 逻辑复用的一些工具函数,分为用于注入 runtime 代码的 helper 和用于简化 AST 操作 的 helper两种。
第一种都在 @babel/helpers 包里,直接 this.addHelper(name) 就可以引入, 而第二种需要手动引入包和调用 api。
前面提到了有的 api 会运行时引入,那 runtime 包里具体有啥呢?
babel runtime
babel runtime 里面放运行时加载的模块,会被打包工具打包到产物中,下面放着各种需要在 runtime 使用的函数,包括三部分:regenerator、corejs、helper。
corejs 这就是新的 api 的 polyfill,分为 2 和 3 两个版本,3 才实现了实例方法的polyfill
regenerator 是 facebook 实现的 aync 的 runtime 库,babel 使用 regenerator-runtime来支持实现 async await 的支持。
helper 是 babel 做语法转换时用到的函数,比如 _typeof、_extends 等
babel 做语法转换和 api 的 polyfill,需要自己实现一部分 runtime 的函数,就是 helper 部分。
有的也没有自己实现,用的第三方的,比如 regenerator 是用的 facebook 的。api 的 polyfill 也是用的 core-js 的,babel 对它们做了整合。
因为 async await 这种特性的实现还是比较复杂的,标准 api 的实现的跟进也需要花精力,所以 babel 直接用了社区的实现。
Babel 的内置功能二
preset-es20xx 到 preset-env
babel6 支持的 preset 是 preset-es2015、preset-es2016、preset-stage-x 等。
也就是根据目标语言版本来指定一系列插件。
但是这样的 preset 设计有个问题:
指定了目标环境支持 es5,但如果目标环境支持了部分 es6(es2015)、es7(es2016)等,那岂不是做了很多没必要的转换?
还有,reset-es2015、preset-es2016、preset-stage-x 这种 preset 跟随版本走的,那岂不是经常变,得经常改这些 preset 的内容 (当某个提案从 stage 0 进入到 stage 1 就得改下),这样多麻烦啊,而且用户也得经常改配置,stage-x 用到了啥对用户来说也是黑盒。
怎么解决这些问题呢?
babel6 到 babel7 的变化给出了答案:
babel7 废弃了 stage-x 和 es20xx 的 preset,改成 preset-env 和 plugin-proposal-xx 的方式。
这样就不需要指定用的是 es 几了,默认会全部支持,包含所有的已经是语言标准特性的 transform plugin。
而且 stage-x 有哪些不再是黑盒,用户想用啥 proposal 的特性直接显示引入对应的 proposal plugin。
做了很多无用的转换的问题通过指定目标环境来解决。
但是目标环境那么多,浏览器版本、node 版本、electron 版本每年都在变,怎么做到精准?
comat-table
答案是 compat-table 的数据,compat-table 提供了每个特性在不同环境中的支持版本。
比如默认参数这个 es2015 的特性,可以查到在 babel6 且 corejs2 以上支持,在 chrome 中是 49 以上支持,chrome48 中还是实验特性,在 node6 以上支持,等等。
光是这些数据还不够,electron 有自己的版本,要支持 electron 得需要 electron 版本和它用的 chromuim 的版本的对应关系。
万幸有 electron-to-chromium 这个项目,它维护了 electron 版本到 chromium 版本的映射关系。
也可以反过来查询 chromium 版本在哪些 electron 版本中使用。
有了这些数据,我们就能知道每一个特性在哪些环境的什么版本支持。
babel7 在 @babel/compat-data 这个包里面维护了这种特性到环境支持版本的映射关系,包括 plugin 实现的特性的版本支持情况(包括 transform 和 proposal ),也包括 corejs 所 polyfill 的特性的版本支持情况。
这样我们就知道每一个特性是在什么环境中支持的了,接下来只要用户指定一个环境,我们就能做到按需转换!
browserslist
那开发者怎么指定环境呢?
让开发者写每个环境的版本是啥肯定不靠谱,这时候就要借助 browerslist 了,它提供了一个从 query (查询表达式) 到对应环境版本的转换。
比如我们可以通过 last 1 version 来查询最新的各环境的版本也可以通过 supports es6-module 查询所有支持 es module 的环境版本
具体查询的语法有很多,可以去 browserslist 的 query 文档中学习,这里就不展开了。
@babel/preset-env
现在有了什么特性在什么环境版本中支持,有了可以通过 query 指定目标环境版本的工具,那么就可以上手改了,从都转成 es5 到根据目标环境确定不支持的特性,只转换这部分特性,这就是 @babel/preset-env 做的事情。
有了 @babel/compat-data 的数据,那么只要用户指定他的目标环境是啥就可以了,这时候可以用 browserslist 的 query 来写,比如 last 1 version, > 1% 这种字符串,babel 会使用 brwoserslist 来把它们转成目标环境具体版本的数据。
有了不同特性支持的环境的最低版本的数据,有了具体的版本,那么过滤出来的就是目标环境不支持的特性,然后引入它们对应的插件即可。这就是 preset-env 做的事情(按照目标环境按需引入插件)。
配置方式比如:
{
"presets": [
["@babel/preset-env", { "targets": "> 0.25%, not dead" }]
]
}
这样就通过 preset-env 解决了多转换了目标环境已经支持的特性的问题。
其实 polyfill 也可以通过 targets 来过滤。
不再手动引入 polyfill,那么怎么引入? 当然是用 preset-env 自动引入了。但是不是默认就会启用这个功能,需要配置。
{
"presets": [
[
"@babel/preset-env",
{
"targets": "> 0.25%, not dead",
"useBuiltIns": "usage",// or "entry" or "false"
"corejs": 3
}
]
]
}
配置下 corejs 和 useBuiltIns。
corejs 就是 babel 7 所用的 polyfill,需要指定下版本,corejs 3 才支持实例方法(比如 Array.prototype.fill )的 polyfill。
useBuiltIns 就是使用 polyfill (corejs)的方式,是在入口处全部引入(entry),还是每个文件引入用到的(usage),或者不引入(false)。
配置了这两个 option 就可以自动引入 polyfill 了。
@babel/preset-env 的配置
targets
targets 是指定编译的目标环境的,可以配 query 或者直接指定环境版本(query 的结果也是环境版本)。
环境有这些:
chrome, opera, edge, firefox, safari, ie, ios, android, node, electron
可以指定 query:
{
"targets": "> 0.25%, not dead"
}
也可以直接指定环境版本;
{
"targets": {
"chrome": "58",
"ie": "11"
}
}
include & exclude
通过 targets 的指定,babel 会自动引入一些插件,但如果觉得自动引入的不大对,也可以手动指定。
当需要手动指定要 include 或者 exclude 什么插件的时候可以使用这个 option。
不过这个只是针对 transform plugin,对于 proposal plugin,要在 plugins 的 option 单独引入。
一般情况下用 preset-env 自动引入的就可以了。
modules
babel 转换代码自然会涉及到模块语法的转换。
modules 就是指定目标模块规范的,取值有 amd、umd、systemjs、commonjs (cjs)、auto、false。
amd、umd、systemjs、commonjs (cjs) 这四个分别指定不同的目标模块规范
false 是不转换模块规范
auto 则是自动探测,默认值也是这个。
其实一般这个 option 都是 bundler 来设置的,因为 bundler 负责模块转换,自然知道要转换成什么模块规范。我们平时就用默认值 auto 即可。
auto 会根据探测到的目标环境支持的模块规范来做转换。依据是在 transform 的时候传入的 caller 数据。
babel.transformFileSync("example.js", {
caller: {
name: "my-custom-tool",
supportsStaticESM: true,
},
});
比如在调用 transformFile 的 api 的时候传入了 caller 是支持 esm 的,那么在 targets 的 modules 就会自动设置为 esm。
debug
我们知道 preset-env 会根据 targets 支持的特性来引入一系列插件。
想知道最终使用了啥插件,那就可以把 debug 设为 true,这样在控制台打印这些数据。
我们知道了 preset-env 能够根据目标环境引入对应的插件,最终会注入 helper 到代码里,但这样还是有问题的:
helper --> runtime
preset-env 会在使用到新特性的地方注入 helper 到 AST 中,并且会引入用到的特性的 polyfill (corejs + regenerator),这样会导致两个问题:
- 重复注入 helper 的实现,导致代码冗余
- polyfill 污染全局环境
解决这两个问题的思路就是抽离出来,然后作为模块引入,这样多个模块复用同一份代码就不会冗余了,而且 polyfill 是模块化引入的也不会污染全局环境。
babel7 通过 preset-env 实现了按需编译和 polyfill,还可以用 plugin-transform-runtime 来变成从 @babel/runtime 包引入的方式。
但这也不是完美的,还有一些问题:
babel7 的问题
babel 中插件的应用顺序是:先 plugin 再 preset,plugin 从左到右,preset 从右到左,这样 plugin-transform-runtime 是在 preset-env 前面的。等 @babel/plugin-transform-runtime 转完了之后,再交给 preset-env 这时候已经做了无用的转换了。而 @babel/plugin-transform-runtime 并不支持 targets 的配置,就会做一些多余的转换和 polyfill。
这个问题在即将到来的 babel8 中得到了解决。
babel8
babel8 提供了 一系列 babel polyfill 的包 ,解决了 babel7 的 @babel/plugin-transform-runtime 的遗留问题,可以通过 targets 来按需精准引入 polyfill。
babel8 支持配置一个 polyfill provider,也就是说你可以指定 corejs2、corejs3、es-shims 等 polyfill,还可以自定义 polyfil。
有了 polyfill 源之后,使用 polyfill 的方式也把之前 transform-runtime 做的事情内置了,从之前的 useBuiltIns: entry、 useBuiltIns: usage 的两种,变成了 3 种:
- entry-global: 这个和之前的 useBuiltIns: entry 对标,就是全局引入 polyfill
- usage-entry: 这个和 useBuiltIns: usage 对标,就是具体模块引入用到的 polyfill。
- usage-pure:这个就是之前需要 transform-runtime 插件做的事情,使用不污染全局变量的 pure 的方式引入具体模块用到的 polyfill.
其实这三种方式 babel 7 也支持,但是 babel8 不再需要 transform-runtime 插件了,而且还支持了 polyfill provider 的配置。
babel 的功能都是通过插件完成的,但是直接指定插件太过麻烦,所以设计出了 preset,我们学习 babel 的内置功能基本等价于学习 preset 的使用。主要是 preset-env、preset-typescript 这些。
但是一些 proposal 的插件需要单独引入,并且 @babel/plugin-transform-runtime也要单独引入。
实战案例:自动埋点
思路分析
import aa from 'aa';
import * as bb from 'bb';
import {cc} from 'cc';
import 'dd';
function a () {
console.log('aaa');
}
class B {
bb() {
return 'bbb';
}
}
const c = () => 'ccc';
const d = function () {
console.log('ddd');
}
import _tracker2 from "tracker";
import aa from 'aa';
import * as bb from 'bb';
import { cc } from 'cc';
import 'dd';
function a() {
_tracker2();
console.log('aaa');
}
class B {
bb() {
_tracker2();
return 'bbb';
}
}
const c = () => {
_tracker2();
return 'ccc';
};
const d = function () {
_tracker2();
console.log('ddd');
};
有两方面的事情要做:
- 引入 tracker 模块。如果已经引入过就不引入,没有的话就引入,并且生成个唯一 id 作为标识符
- 对所有函数在函数体开始插入 tracker 的代码
代码实现
模块引入
引入模块这种功能显然很多插件都需要,这种插件之间的公共函数会放在 helper,这里我们使用 @babel/helper-module-imports。
const importModule = require('@babel/helper-module-imports');
// 省略一些代码
importModule.addDefault(path, 'tracker',{
nameHint: path.scope.generateUid('tracker')
})
首先要判断是否被引入过:在 Program 根结点里通过 path.traverse 来遍历 ImportDeclaration,如果引入了 tracker 模块,就记录 id 到 state,并用 path.stop 来终止后续遍历;没有就引入 tracker 模块,用 generateUid 生成唯一 id,然后放到 state。
当然 default import 和 namespace import 取 id 的方式不一样,需要分别处理下。
我们把 tracker 模块名作为参数传入,通过 options.trackerPath 来取。
Program: {
enter (path, state) {
path.traverse({
ImportDeclaration (curPath) {
const requirePath = curPath.get('source').node.value;
if (requirePath === options.trackerPath) {// 如果已经引入了
const specifierPath = curPath.get('specifiers.0');
if (specifierPath.isImportSpecifier()) {
state.trackerImportId = specifierPath.toString();
} else if(specifierPath.isImportNamespaceSpecifier()) {
state.trackerImportId = specifierPath.get('local').toString();// tracker 模块的 id
}
path.stop();// 找到了就终止遍历
}
}
});
if (!state.trackerImportId) {
state.trackerImportId = importModule.addDefault(path, 'tracker',{
nameHint: path.scope.generateUid('tracker')
}).name; // tracker 模块的 id
state.trackerAST = api.template.statement(`${state.trackerImportId}()`)();// 埋点代码的 AST
}
}
}
我们在记录 tracker 模块的 id 的时候,也生成调用 tracker 模块的 AST,使用 template.statement.
函数插桩
函数插桩要找到对应的函数,这里要处理的有:ClassMethod、ArrowFunctionExpression、FunctionExpression、FunctionDeclaration 这些节点。
当然有的函数没有函数体,这种要包装一下,然后修改下 return 值。如果有函数体,就直接在开始插入就行了。
'ClassMethod|ArrowFunctionExpression|FunctionExpression|FunctionDeclaration'(path, state) {
const bodyPath = path.get('body');
if (bodyPath.isBlockStatement()) { // 有函数体就在开始插入埋点代码
bodyPath.node.body.unshift(state.trackerAST);
} else { // 没有函数体要包裹一下,处理下返回值
const ast = api.template.statement(`{${state.trackerImportId}();return PREV_BODY;}`)({PREV_BODY: bodyPath.node});
bodyPath.replaceWith(ast);
}
}